1999年Castro和Liskov在《操作系统设计与实现》上发表论文Practical Byzantine Fault Tolerance。之后Castro和Liskov修改了之前论文的部分细节,2001年将修改后的论文Practical Byzantine Fault Tolerance and Proactive Recovery发表于《ACM Transactions on Computer Systems (TOCS)》。之后发表的这篇论文对之前的论文进行了部分优化,pre-prepare消息不再包含请求消息(只包含消息摘要),client不只把请求发给主节点(也发给从节点)等。fabric中的pbft实现也是基于2001年的论文,因此建议大家直接看2001年发表的论文。但是因为,网上对1999年的论文讲解比较多,本文也以1999年的论文形成总结。
0. 背景
拜占庭问题(Byzantine Problem) 又叫拜占庭将军(Byzantine Generals Problem) 问题,讨论的是允许存在少数节点作恶(消息可能被伪造) 场景下的如何达成共识问题。拜占庭容错(Byzantine Fault Tolerant,BFT)讨论的是容忍拜占庭错误的共识算法。
- 两将军问题
拜占庭问题之前,学术界就已经存在两将军问题的讨论(《Some constraints and tradeofis in the design of network communications》 ,1975年):两个将军要通过信使来达成进攻还是撤退的约定,但信使可能迷路或被敌军阻拦(消息丢失或伪造),如何达成一致?根据FLP不可能原理,这个问题无通用解。
- 拜占庭问题
拜占庭问题最早由 Leslie Lamport 等学者于 1982 年在论文《The Byzantine Generals Problem》中正式提出,是用来解释异步系统中共识问题的一个虚构模型。它是分布式领域中最复杂、最严格的容错模型。在该模型下,系统不会对集群中的节点做任何的限制,它们可以向其他节点发送随机数据、错误数据,也可以选择不响应其他节点的请求,这些无法预测的行为使得容错这一问题变得更加复杂。
拜占庭是古代东罗马帝国的首都,由于地域宽广,假设其守卫边境的多个将军(系统中的多个节点) 需要通过信使来传递消息,达成某些一致决定。但由于将军中可能存在叛徒(系统中节点出错),这些叛徒将向不同的将军发送不同的消息,试图干扰共识的达成。拜占庭问题即讨论在此情况下,如何让忠诚的将军们能达成行动的一致。
在大多数的分布式系统中,拜占庭的场景并不多见。然而在特定场景下存在意义,例如允许匿名参与的系统(如比特币) ,或是出现欺诈可能造成巨大损失的情况。
- 拜占庭容错算法
拜占庭容错算法(Byzantine Fault Tolerant)是面向拜占庭问题的容错算法,解决的是在网络通信可靠,但节点可能故障和作恶情况下如何达成共识。
拜占庭容错算法最早的讨论可以追溯到Leslie Lamport等人1982年发表的论文《The Byzantine Generals Problem》,之后出现了大量的改进工作,代表性成果包括《Optimal Asynchronous Byzantine Agreement》(1992年)、《Fully Polynomial Byzantine Agreement for n>3t Processors in t+1 Rounds》(1998年)等。长期以来,拜占庭问题的解决方案都存在运行过慢,或复杂度过高的问题,直到“实用拜占庭容错算法”(Practical Byzantine Fault Tolerance,PBFT)算法的提出。
1999年,这一算法由Castro和Liskov于论文《Practical Byzantine Fault Tolerance》中提出。该算法基于前人工作(特别是Paxos相关算法,因此也被称为Byzantine Paxos)进行了优化,首次将拜占庭容错算法复杂度从指数级降低到了多项式级,目前已得到广泛应用。其可以在恶意节点不超过总数1/3的情况下同时保证Safety和Liveness。
PBFT算法采用密码学相关技术(RSA签名算法、消息验证编码和摘要)确保消息传递过程无法被篡改和破坏。
算法整体的基本过程如下:
-
首先,通过轮换或随机算法选出某个节点为主节点,此后只要主节点不切换,则称为一个视图(View) 。
-
在某个视图中,客户端将请求<REQUEST,operation,timestamp,client> 发送给主节点,主节点负责广播请求到所有其它副本节点。
-
所有节点处理完成请求,将处理结果 <REPLY,view,timestamp,client,id_node,response>返回给客户端。客户端检查是否收到了至少 f+1 个来自不同节点的相同结果,作为最终结果。
主节点广播过程包括三个阶段的处理:预准备(Pre-Prepare)、准备(Prepare)和提交(Commit)。预准备和准备阶段确保在同一个视图内请求发送的顺序正确;准备和提交阶段则确保在不同视图之间的确认请求是保序的。接下来详细解释pbft算法流程。
1. pbft
1.1 算法流程
pbft算法通过三阶段广播协议来使所有正常节点按相同的顺序执行请求,三阶段分别为pre-prepare、prepare和commit。pre-prepare阶段和prepare阶段确保了在同一个view下,正常节点对于消息m达成了全局一致的顺序,用(Order<v, m, n>)表示,在view = v下,正常节点都会对消息m,确认一个序号n。接下来的commit投票,再配合上viewchange的设计,实现了即使view切换,也可以保证对于m的全局一致顺序,即(Order<v+1, m, n>),视图切换到v+1, 依然会对消息m,确认序号n。
三阶段协议
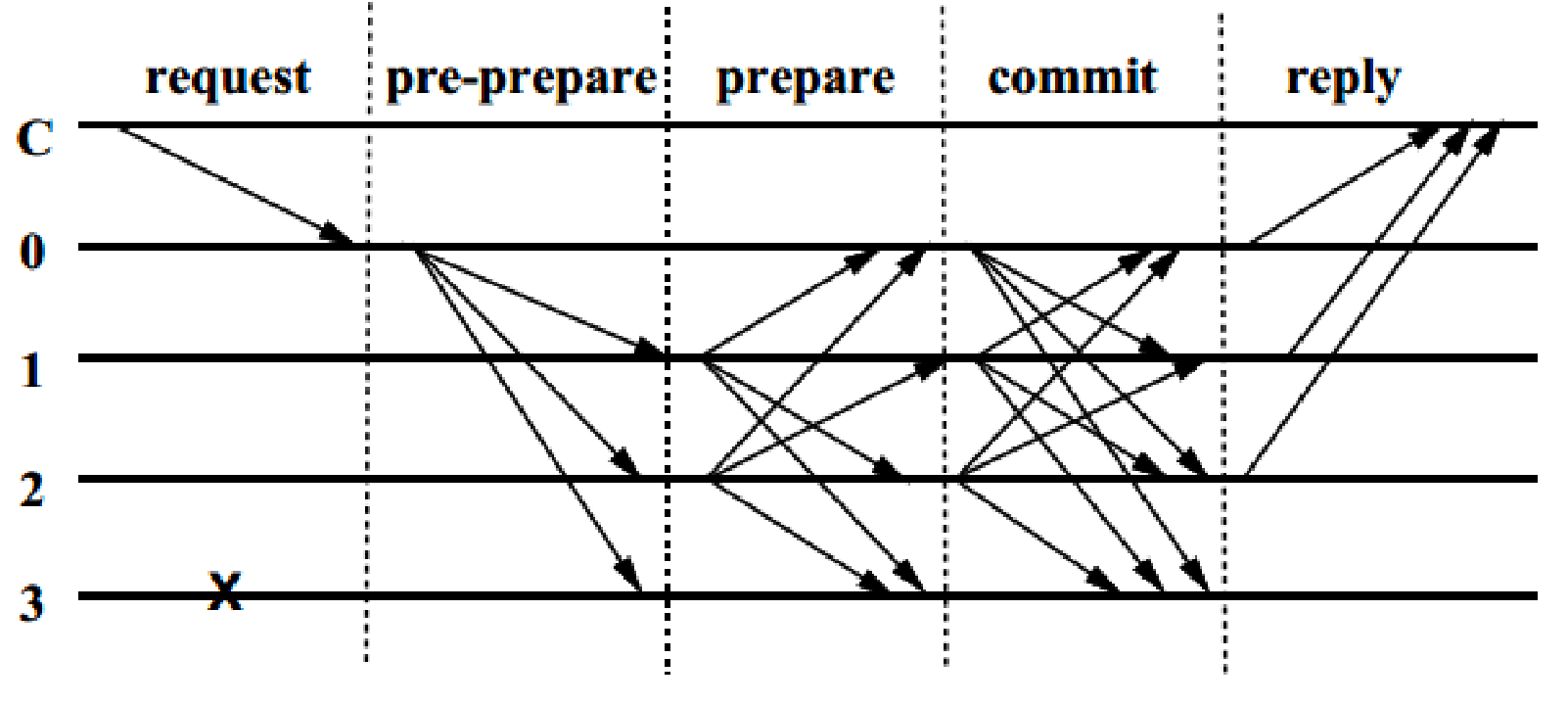
三阶段协议数据结构

- pre-prepare
pre-prepare阶段的消息格式(«PRE-PREPARE, v, n, d>sigma(p), m>),其中v表示当前view编号,n表示给m分配的序号,d为m的哈希,以及m的原文。
节点收到请求m时,会做两件事,首先,广播pre-prepare消息给其他节点。然后,将消息保存在本地log中。
其他从节点收到pre-prepare消息时,会依次验证:
- 签名验证
- 检测v是否合法
- 检测n是否合法(相同、间隔、是否在水线<h, H>之内)
总结:
主节点发出pre-prepare消息,从节点验证消息的正确性(客户端签名、视图、请求编号);一旦消息验证正确,则pre-prepare阶段完成,从节点广播prepare消息,进入prepare阶段;之后,节点将消息加入到本地的log中。
- prepare
prepare阶段的消息格式(<PREPARE, v, n, d, i>sigma(i)),其中v表示当前view编号,n表示给m分配的序号,d为m的哈希。
所有节点收到prepare消息时,会依次验证:
- 签名验证
- 检测v是否合法
- 检测n是否合法(相同、间隔、是否在水线<h, H>之内)
节点收到2f+1个该消息编号的prepare消息,则表明prepare阶段完成,节点达成了prepared状态,记为prepared(m,v,n,i),节点广播commit消息,同时进入commit阶段;
至此,可以确保在view不发生切换的情况下,对于消息m有全局一致的顺序。
也就是说,在view不变的情况的下:
(1) 一个正常节点i,不能对两个及以上的不同消息,达成相同序号n的prepared状态。即不能同时存在prepared(m,v,n,i)和prepared(m',v,n,i)
(2) 两个正常节点i、j,必须对相同的消息m,达成相同序号n的prepared状态。prepared(m,v,n,i) && prepared(m,v,n,j)
证明:
(1) 假如正常节点i, 对于消息m达成了prepared(m,v,n,i),同时存在一个m',也达成了prepared(m',v,n,i)。
首先对于prepared(m,v,n,i),肯定有2m+1个节点发出了<prepare,m,v,n>消息。
对于prepared(m',v,n,i),肯定也有2m+1个节点发出了<prepare,m',v,n>。
2*(2f+1) - (3f+1) = f+1
所以至少有f+1个节点,既发出了<prepare,m,v,n>,又发出了<prepare,m',v,n>,这明显是拜占庭行为。也就是说,至少有f+1个拜占庭节点,而这与容错条件相矛盾。
(2) 假如两个正常节点i、j,分别对不同的消息m、m',达成序号n的prepared状态,prepared(m,v,n,i)和prepared(m',v,n,j)
首先对于prepared(m,v,n,i),肯定有2m+1个节点发出了<prepare,m,v,n>消息。
对于prepared(m',v,n,j),肯定也有2m+1个节点发出了<prepare,m',v,n>。
2*(2f+1) - (3f+1) = f+1
所以至少有f+1个节点,既发出了<prepare,m,v,n>,又发出了<prepare,m',v,n>,这明显是拜占庭行为。也就是说,至少有f+1个拜占庭节点,而这与容错条件相矛盾。
prepared状态是十分重要的,当涉及到view转换时,为了保证view切换前后的safety特性,需要将上一轮view的信息传递到新的view,而在pbft中就是将prepared状态信息传递到新的view。可以这么理解,新的view中需要在上一轮view的prepared信息基础上,继续进行共识。
总结:
节点收到prepare消息,节点验证消息的正确性(签名、视图、请求编号);一旦2f+1个prepare消息验证正确,则prepare阶段完成,节点广播commit消息,同时进入commit阶段;之后,节点将消息加入到本地的log中。
- commit
commit阶段的消息格式(<COMMIT, v, n, d, i>sigma(i)),其中v表示当前view编号,n表示给m分配的序号,d为m的哈希。
其他从节点收到commit消息时,会依次验证:
- 签名验证
- 检测v是否合法
- 检测n是否合法(相同、间隔、是否在水线<h, H>之内)
节点接收commit消息后,会像收到prepare消息一样进行几步验证已确定是否接受该消息。
当节点i,达成了prepared(m,v,n,i)状态,并且收到了(2f+1)个commit(v,n,d,i)消息,则该节点达成了commit-local(m,v,n,i)状态。
达成commit-local之后,节点对于消息m就有了一个全局一致的顺序,可以执行该消息并reply to客户端了。
commit-local状态说明有2f+1个节点达成了prepared状态.
总结:
节点收到2f+1个该消息编号的commit消息,则commit阶段完成,节点执行客户端请求操作。
1.2 垃圾回收
为了节省内存,系统需要一种将日志中的无异议消息记录删除的机制。为了保证系统的安全性,副本节点在删除自己的消息日志前,需要确保至少f+1个正常副本节点执行了消息对应的请求,并且可以在视图变更时向其他副本节点证明。另外,如果一些副本节点错过部分消息,但是这些消息已经被所有正常副本节点删除了,这就需要通过传输部分或者全部服务状态实现该副本节点的同步。因此,副本节点同样需要证明状态的正确性。
在每一个操作执行后都生成这样的证明是非常消耗资源的。因此,证明过程只有在请求序号可以被某个常数(比如100)整除的时候才会周期性地进行。我们将这些请求执行后得到的状态称作检查点(checkpoint),并且将具有证明的检查点称作稳定检查点(stable checkpoint)。
副本节点保存了服务状态的多个逻辑拷贝,包括最新的稳定检查点,零个或者多个非稳定的检查点,以及一个当前状态。写时复制技术可以被用来减少存储额外状态拷贝的空间开销。
检查点的正确性证明的生成过程如下:当副本节点i生成一个检查点后,向其他副本节点广播检查点消息<CHECKPOINT,n,d,i>,这里n是最近一个影响状态的请求序号,d是状态的摘要。每个副本节点都默默地在各自的日志中收集并记录其他节点发过来的检查点消息,直到收到来自2f+1个不同副本节点的具有相同序号n和摘要d的检查点消息。这2f+1个消息就是这个检查点的正确性证明。
具有证明的检查点成为稳定检查点,然后副本节点就可以将所有序号小于等于n的预准备、准备和确认消息从日志中删除。同时也可以将之前的检查点和检查点消息一并删除。
检查点协议可以用来更新水线(watermark)的高低值(h和H),这两个高低值限定了可以被接受的消息。水线的低值h与最近稳定检查点的序列号相同,而水线的高值H=h+k,k需要足够大才能使副本不至于为了等待稳定检查点而停顿。加入检查点每100个请求产生一次,k的取值可以是200。
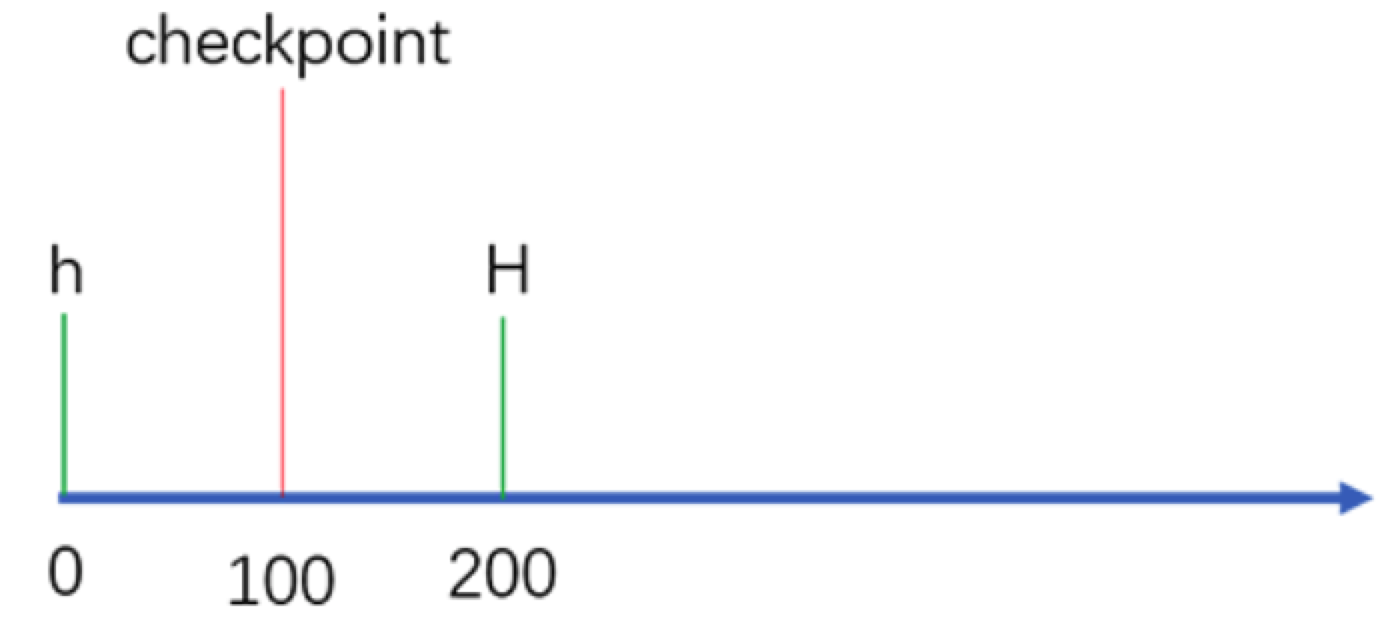
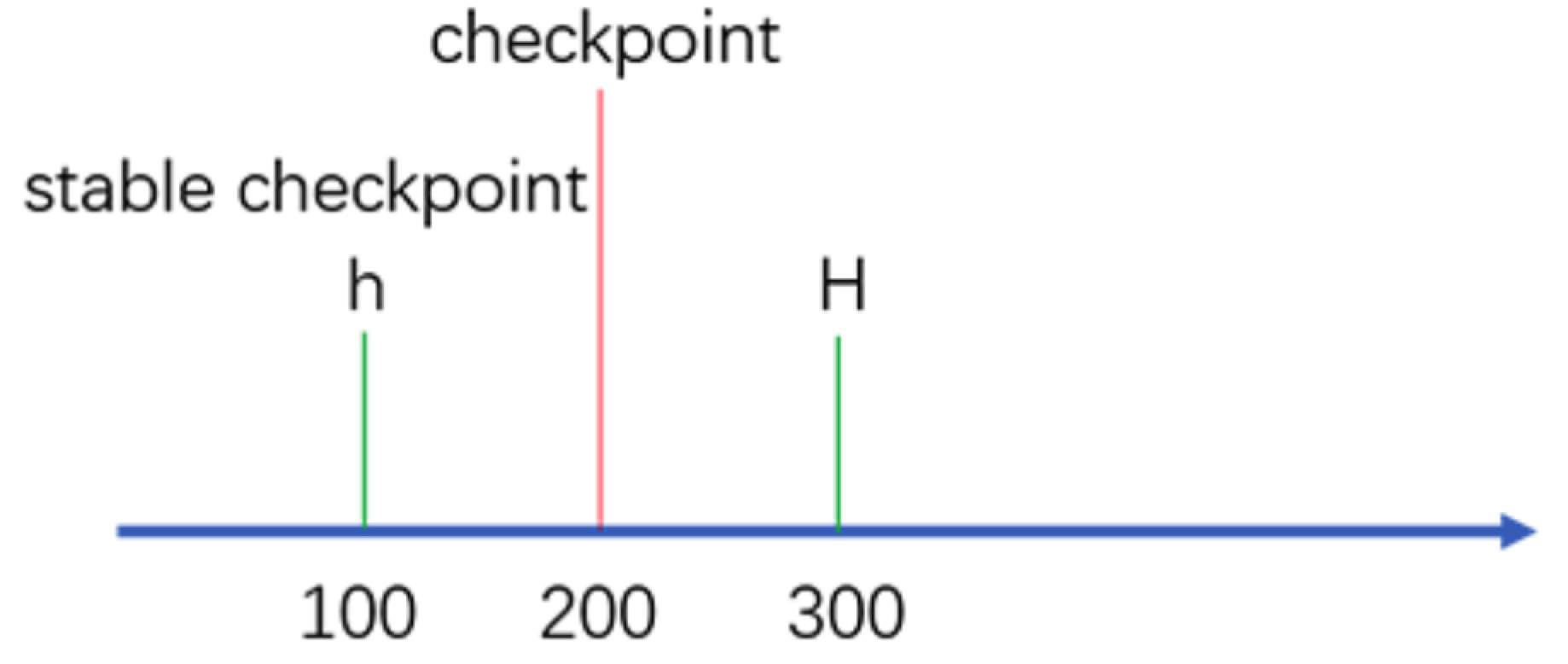
举例:
stable checkpoint 就是大部分节点 (2f+1) 已经共识完成的最大请求序号。比如系统有 4 个节点,三个节点都已经共识完了的请求编号是 100 ,那么这个 100 就是 stable checkpoint 了。那设置这个 stable checkpoint 有什么作用呢?最大的目的就是减少内存的占用。因为每个节点应该记录下之前曾经共识过什么请求,但如果一直记录下去,数据会越来越大,所以应该有一个机制来实现对数据的删除。那怎么删呢?很简单,比如现在的稳定检查点是 100 ,那么代表 100 号之前的记录已经共识过的了,所以之前的记录就可以删掉了。
1.3 视图变更
如果主节点作恶,它可能会给不同的请求编上相同的序号,或者不去分配序号,或者让相邻的序号不连续。备份节点应当有职责来主动检查这些序号的合法性。如果主节点掉线或者作恶不广播客户端的请求,客户端设置超时机制,超时的话,向所有副本节点广播请求消息。副本节点检测出主节点作恶或者下线,发起View Change消息。
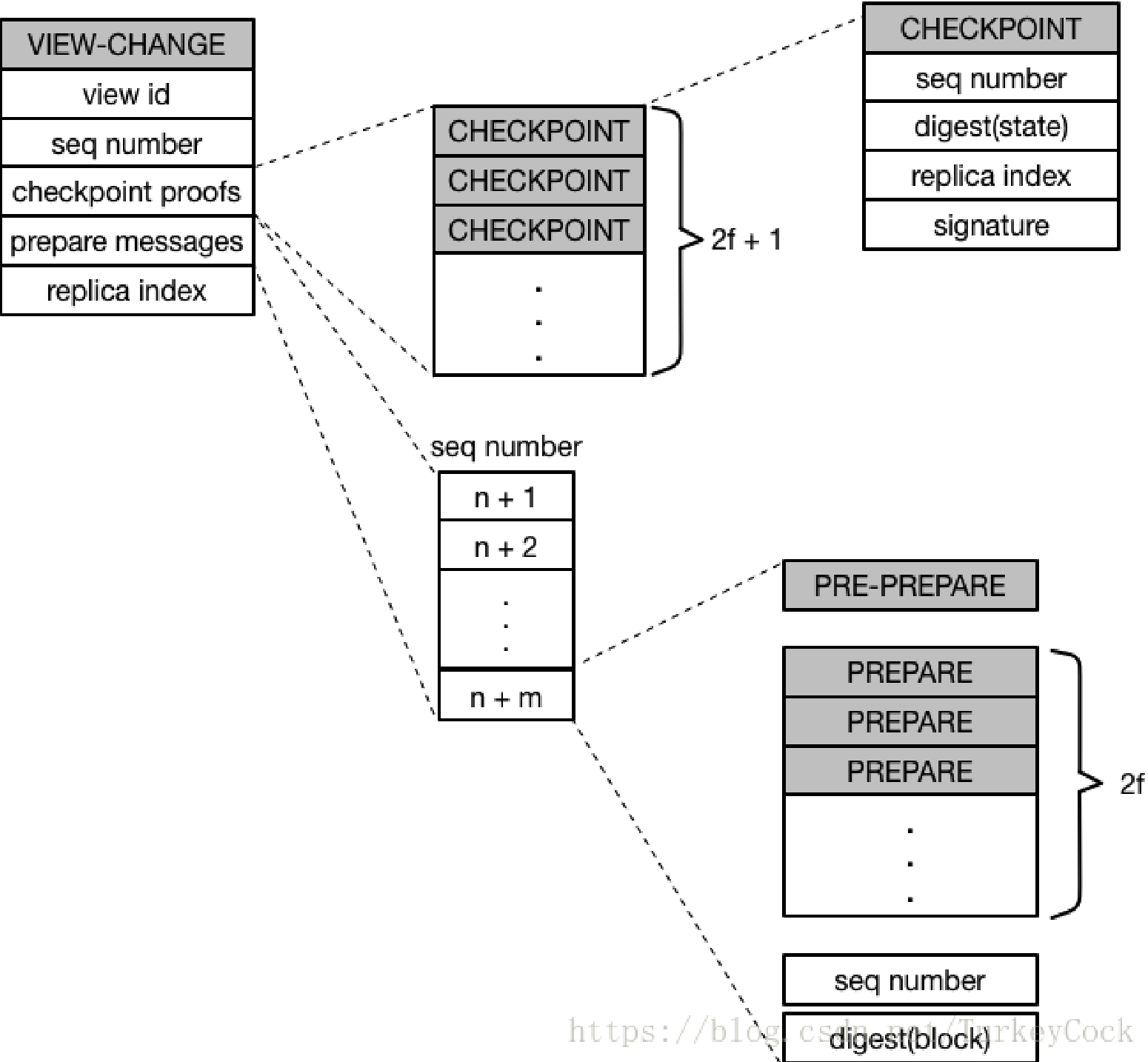
VIEW-CHANGE
<VIEW-CHANGE, v+1, n, C, P, i>sigma(i)消息。n是最新的stable checkpoint的编号,C是2f+1验证过的CheckPoint消息集合,P是当前副本节点未完成的请求的PRE-PREPARE和PREPARE消息集合。
NEW-VIEW
<NEW-VIEW, v+1, V, O>sigma(p)消息。V是有效的VIEW-CHANGE消息集合。O是主节点重新发起的未经完成的PRE-PREPARE消息集合。PRE-PREPARE消息集合的选取规则:
- 选取V中最小的stable checkpoint编号min-s,选取V中prepare消息的最大编号max-s。
- 在min-s和max-s之间,如果存在P消息集合,则创建«PRE-PREPARE, v+1, n, d>, m>消息。否则创建一个空的PRE-PREPARE消息,即:«PRE-PREPARE, v+1, n, d(null)>, m(null)>, m(null)空消息,d(null)空消息摘要。
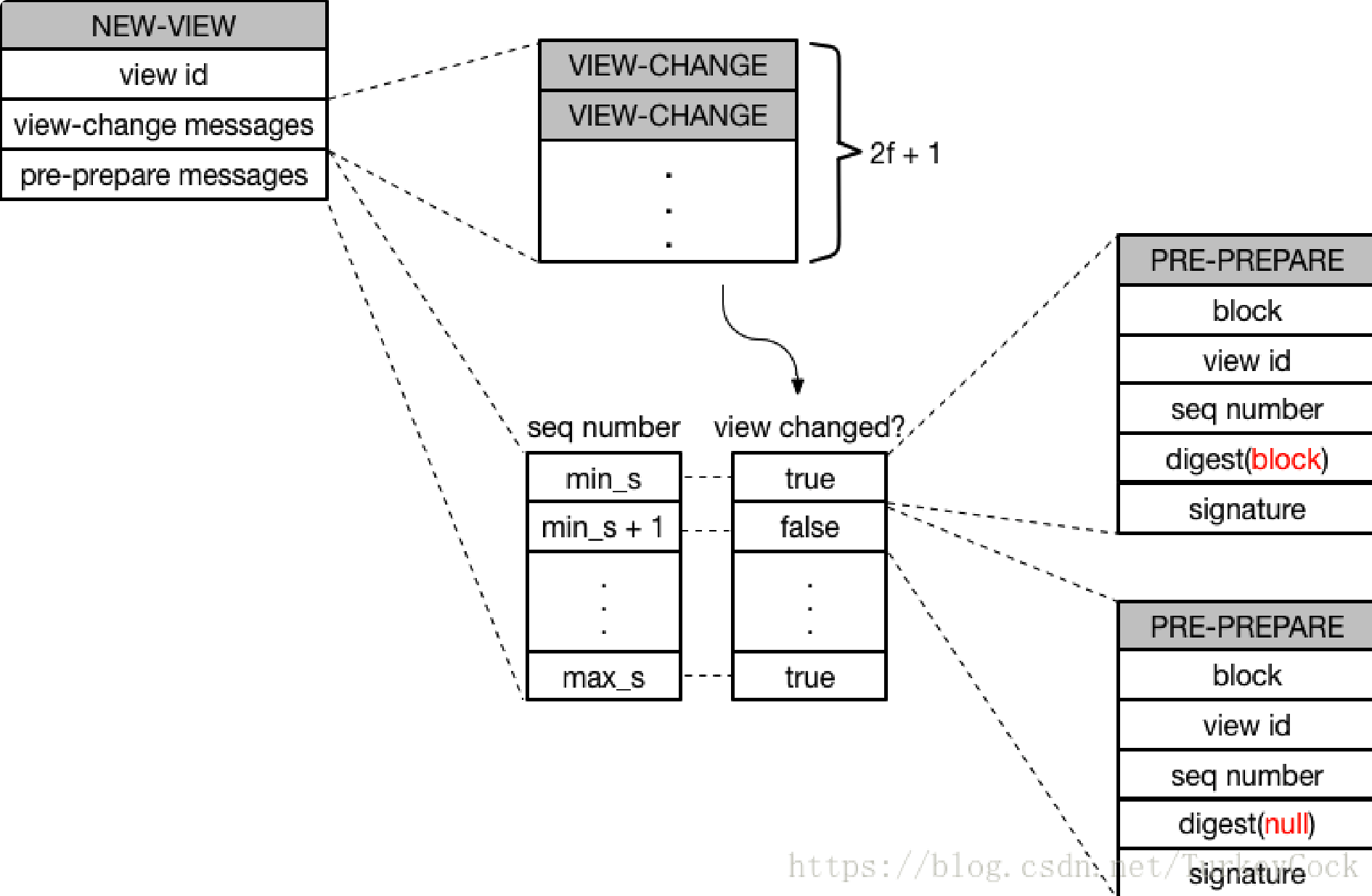
当主节点p = v + 1 mod |R|收到2f个有效的VIEW-CHANGE消息后,向其他节点广播<NEW-VIEW, v+1, V, O>sigma(p)消息,副本节点收到主节点的NEW-VIEW消息,验证有效性,有效的话,进入v+1状态,并且开始O中的PRE-PREPARE消息处理流程。
总结:
可以这样理解,在新的view中,节点是在上一轮view中各个节点的prepared状态基础上进行共识流程的。
Notes:
发生view转换时,需要的保证的是:如果视图转换之前的消息m被分配了序号n, 并且达到了prepared状态,那么在视图转换之后,该消息也必须被分配序号n(safety特性)。因为达到prepared状态以后,就有可能存在某个节点commit-local。要保证对于m的commit-local,在视图转换之后,其他节点的commit-local依然是一样的序号。
1.4 pbft优化
- 减少通信
- 指定一个节点回复client完整的执行结果,其他节点只回复结果摘要;如果对比摘要不一致,重新发送该请求,并等待所有节点的完整结果。
节省了带宽 - 节点到达prepared状态就执行请求,节点将这个临时执行结果回复给client端。如果client收到2f+1个临时回复,就能保证该请求最终也是以这个结果提交的。否则,走三阶段常规流程,等待f+1个一致回复。
省略了comimit阶段 - 对于只读操作,client将请求广播给所有节点,之后的流程同上。
省略了pre-prepare阶段
- 指定一个节点回复client完整的执行结果,其他节点只回复结果摘要;如果对比摘要不一致,重新发送该请求,并等待所有节点的完整结果。
- 只在view-change和new-view时才采用数字签名,其他所有消息采用消息验证码(MACs)认证。
2. 新的解决思路
拜占庭问题之所以难解,在于任何时候系统中都可能存在多个提案(因为提案成本很低),并且在大规模场景下要完成最终确认的过程容易受干扰,难以达成共识。
2014 年,斯坦福的 Christopher Copeland 和 Hongxia Zhong 在论文《Tangaroa: a byzantine fault tolerant raft》 中提出在 Raft 算法基础上借鉴 PBFT 算法的一些特性(包括签名、恶意领导探测、选举校验等) 来实现拜占庭容错性,兼顾可实现性和鲁棒性。该论文也启发了Kadena 等项目的出现,实现更好性能的拜占庭算法。
2017年,MIT计算机科学与人工智能实验室(CSAIL)的Yossi Gilad和Silvio Micali等人在论文《Algorand: Scaling Byzantine Agreements for Cryptocurrencies》 中针对PBFT算法在很多节点情况下性能不佳的问题,提出先选出少量记账节点,然后再利用可验证随机函数(Verifiable Random Function,VRF)来随机选取领导节点,避免全网直接做共识,将拜占庭算法扩展到了支持较大规模的应用场景,同时保持较好的性能(1000+ tps)。
此外,康奈尔大学的Rafael Pass和Elaine Shi在论文《The Sleepy Model of Consensus》中还探讨了在动态场景(大量节点离线情况)下如何保障共识的安全性,所提出的Sleepy Consensus算法可以在活跃诚实节点达到一半以上时确保完成拜占庭共识。
2018年,清华大学的Chenxing Li等在论文《Scaling Nakamoto Consensus to Thousands of Transactions per Second》中提出了Conflux共识协议。该协议在 GHOST算法基础上改善了安全性,面向公有区块链场景下,理论上能达到6000+ tps。
比特币网络在设计时使用了PoW(Proof of Work)的概率型算法思路,从如下两个角度解决大规模场景下的拜占庭容错问题。
首先,限制一段时间内整个网络中出现提案的个数(通过工作量证明来增加提案成本);其次是丢掉最终确认的约数,约定好始终沿着已知最长的链进行拓展。共识的最终确认是概率意义上的存在。这样,即便有人试图恶意破坏,也会付出相应的经济代价(超过整体系统一半的工作量) 。
后来的各种 PoX 系列算法,也都是沿着这个思路进行改进,采用经济博弈来制约攻击者。
参考文献
Practical Byzantine Fault Tolerance


评论