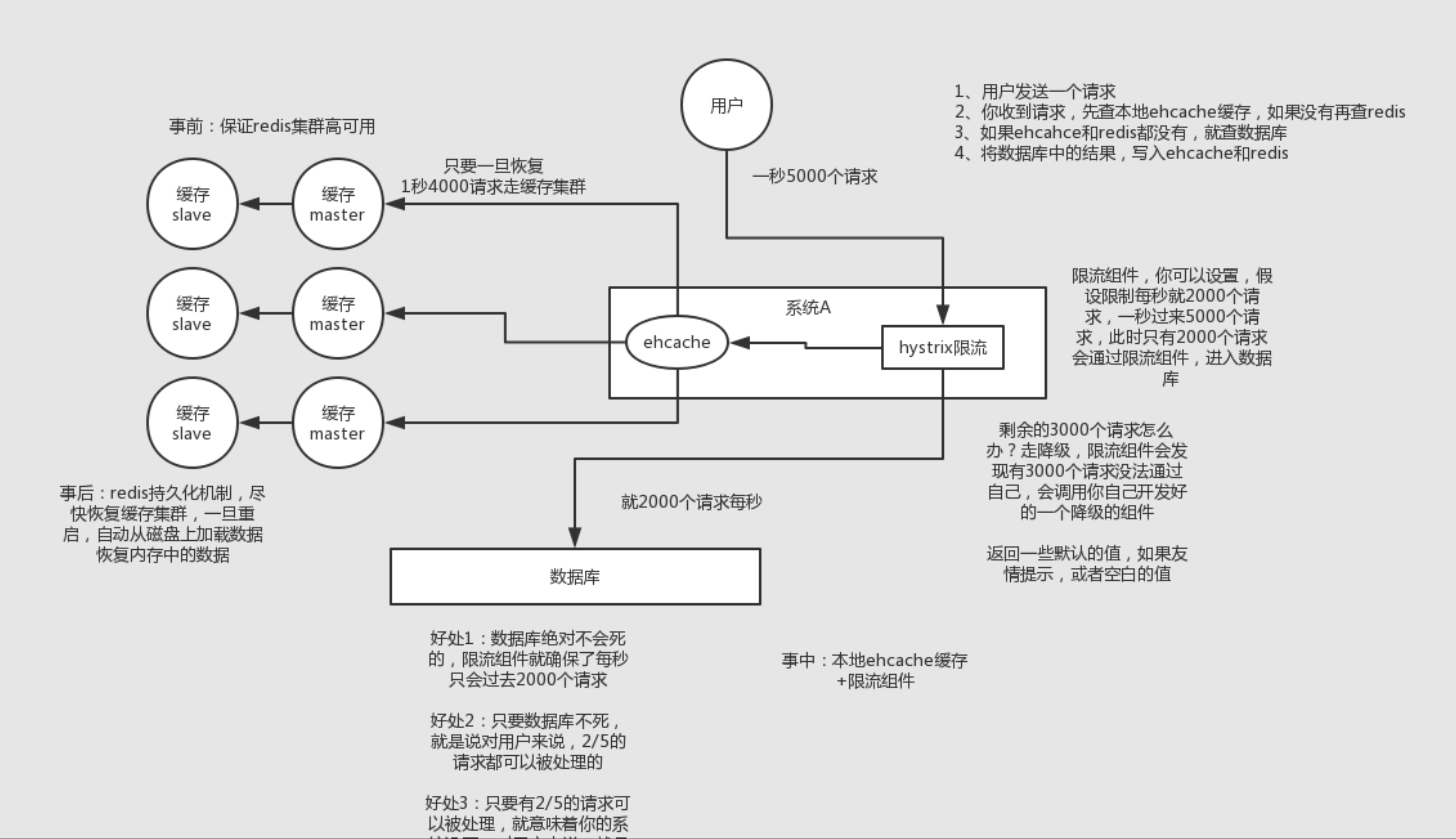
1. 缓存雪崩
1.1 什么是缓存雪崩?
简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
1.2 有哪些解决办法?
- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
2. 缓存穿透
2.1 什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
2.1 有哪些解决办法?
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
- 缓存无效 key(解决请求的 key 变化不频繁的情况) : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:SET key value EX 10086。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建的不同的请求key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
- 布隆过滤器(解决请求的 key 变化频繁且key非法):布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
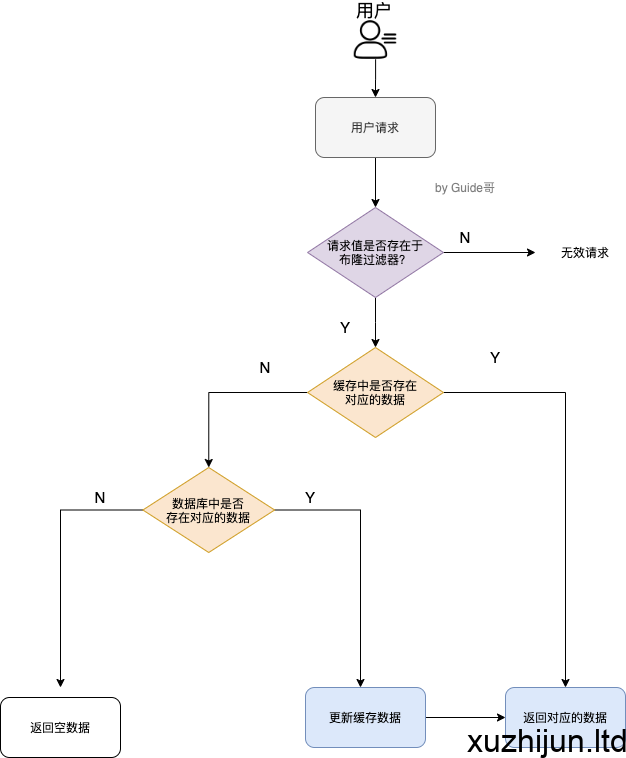
但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是: 布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
- 缓存预热(解决请求的 key 变化频繁且key合法):提前将需要做缓存的数据放入redis,即缓存预热。
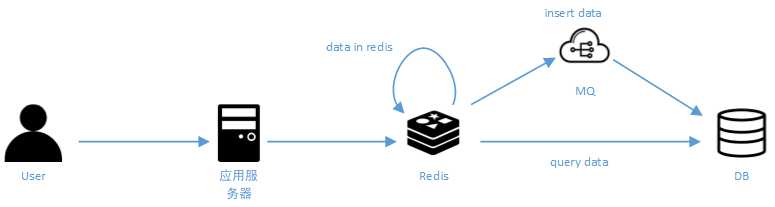
3. 消息队列削峰填谷
如果刚上线某个功能,大量用户同时点这个功能,并发量大的话,请求走到后台,那么写库的操作就非常多,数据库连接数突然激增,数据库会顶不住吧。
所以为避免流量集中落到数据库,此时我们可以使用消息队列MQ。将插入操作的请求发往消息队列,使插入操作以一定的速率到数据库执行,使得对数据库的请求数尽量平滑,消息发给消息队列立即返回给前端成功,不用等待插库完成,用MQ实现了异步解耦,削峰填谷。


评论