1. Zookeeper 核心架构设计
1.1 Zookeeper 特点
(1)Zookeeper 是一个分布式协调服务,是为了解决多个节点状态不一致的问题,充当中间机构来调停。如果出现了不一致,则把这个不一致的情况写入到 Zookeeper 中,Zookeeper 会返回响应,响应成功,则表示帮你达成了一致。
比如,A、B、C 节点在集群启动时,需要推举出一个主节点,这个时候,A、B、C 只要同时往 Zookeeper 上注册临时节点,谁先注册成功,谁就是主节点。
(2)Zookeeper 虽然是一个集群,但是数据并不是分散存储在各个节点上的,而是每个节点都保存了集群所有的数据。
其中一个节点作为主节点,提供分布式事务的写服务,其他节点和这个节点同步数据,保持和主节点状态一致。
(3)Zookeeper 所有节点的数据状态通过 Zab 协议保持一致。当集群中没有 Leader 节点时,内部会执行选举,选举结束,Follower 和 Leader 执行状态同步;当有 Leader 节点时,Leader 通过 ZAB 协议主导分布式事务的执行,并且所有的事务都是串行执行的。
(4)Zookeeper 的节点个数是不能线性扩展的,节点越多,同步数据的压力越大,执行分布式事务性能越差。推荐3、5、7 这样的数目。
1.1 Zookeeper 角色的理解
Zookeeper 并没有沿用 Master/Slave 概念,而是引入了 Leader,Follower,Observer 三种角色。
通过 Leader 选举算法来选定一台服务器充当 Leader 节点,Leader 服务器为客户端提供读、写服务。
Follower 节点可以参加选举,也可以接受客户端的读请求,但是接受到客户端的写请求时,会转发到 Leader 服务器去处理。
Observer 角色只能提供读服务,不能选举和被选举,所以它存在的意义是在不影响写性能的前提下,提升集群的读性能。
1.3 Zookeeper 同时满足了 CAP 吗?
答案是否,CAP 只能同时满足其二。
Zookeeper 是有取舍的,它实现了 A 可用性、P 分区容错性、C 的写入一致性,牺牲的是 C的读一致性。
也就是说,Zookeeper 并不保证读取的一定是最新的数据。如果一定要最新,需要使用 sync 回调处理。
⚠️⚠️⚠️
大部分文章指出Zookeeper保证的是CP,牺牲掉可用性:
不能保证每次服务请求的可用性。任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
进行leader选举时集群都是不可用。在使用ZooKeeper获取服务列表时,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。所以说,ZooKeeper不能保证服务可用性。
2. 核心机制一:ZNode 数据模型
Zookeeper 的 ZNode 模型其实可以理解为类文件系统,如下图:
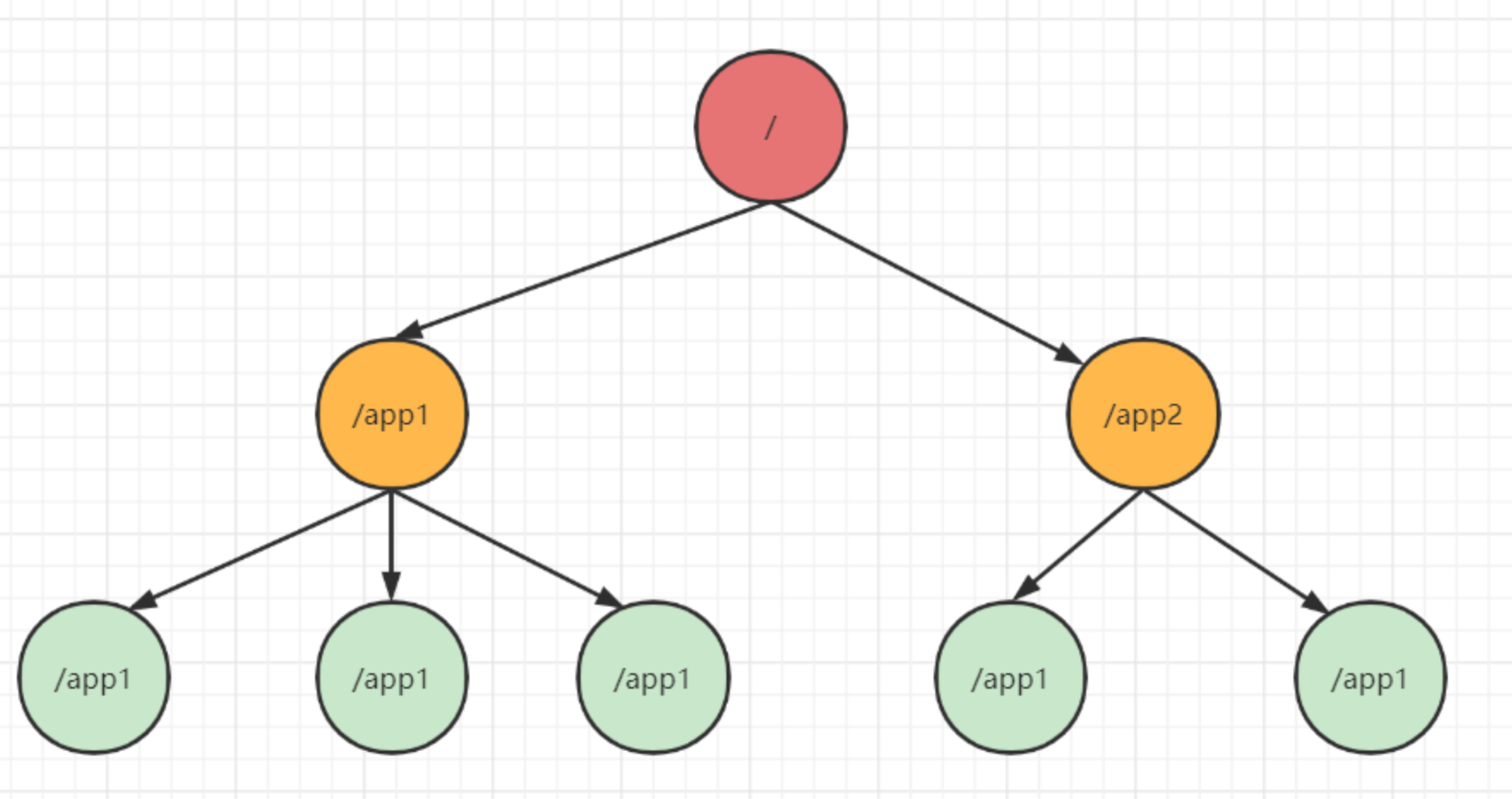
2.1 ZNode 并不适合存储太大的数据
为什么是类文件系统呢?因为 ZNode 模型没有文件和文件夹的概念,每个节点既可以有子节点,也可以存储数据。
那么既然每个节点可以存储数据,是不是可以任意存储无限制的数据呢?答案是否定的。在 Zookeeper 中,限制了每个节点只能存储小于 1 M 的数据,实际应用中,最好不要超过 1kb。
原因有以下四点:
- 同步压力:Zookeeper 的每个节点都存储了 Zookeeper 的所有数据,每个节点的状态都要保持和 Leader 一致,同步过程至少要保证半数以上的节点同步成功,才算最终成功。如果数据越大,则写入的难度也越大。
- 请求阻塞:Zookeeper 为了保证写入的强一致性,会严格按照写入的顺序串行执行,某个时刻只能执行一个事务。如果上一个事务执行耗时比较长,会阻塞后面的请求;
- 存储压力:正是因为每个 Zookeeper 的节点都存储了完整的数据,每个 ZNode 存储的数据越大,则消耗的物理内存也越大;
- 设计初衷:Zookeeper 的设计初衷,不是为了提供大规模的存储服务,而是提供了这样的数据模型解决一些分布式问题。
除非集群是以ZNode为单位进行同步的,否则以上四点不能算作限定ZNode大小的原因
2.2 ZNode 的分类
(1)按生命周期分类
按照声明周期,ZNode 可分为永久节点和临时节点。
很好理解,永久节点就是要显示的删除,否则会一直存在;临时节点,是和会话绑定的,会话创建的所有节点,会在会话断开连接时,全部被 Zookeeper 系统删除。
(2)按照是否带序列号分类
带序列号的话,比如在代码中创建 /a 节点,创建之后其实是 /a000000000000001,再创建的话,就是 /a000000000000002,依次递增
不带序号,就是创建什么就是什么
(3)所以,一共有四种 ZNode
- 永久的不带序号的
- 永久的带序号的
- 临时的不带序号的
- 临时的带序号的
(4)注意的点
临时节点下面不能挂载子节点,只能作为其他节点的叶子节点。
2.3 代码实战
ZNode 的数据模型其实很简单,只有这么多知识。下面用代码来巩固一下。
这里我们使用 curator 框架来做 demo。(当然,你可以选择使用 Zookeeper 官方自带的 Api)
引入 pom 坐标:
<!-- curator-framework -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.2.0</version>
</dependency>
<!-- curator-recipes -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>
代码:
public class ZkTest {
// 会话超时
private final int SESSION_TIMEOUT = 30 * 1000;
// 连接超时 、 有啥区别
private static final int CONNECTION_TIMEOUT = 3 * 1000;
private static final String CONNECT_ADDR = "localhost:2181";
private CuratorFramework client = null;
public static void main(String[] args) throws Exception {
// 创建客户端
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(CONNECT_ADDR)
.connectionTimeoutMs(CONNECTION_TIMEOUT)
.retryPolicy(retryPolicy)
.build();
client.start();
System.out.println(ZooKeeper.States.CONNECTED);
System.out.println(client.getState());
// 创建节点 /test1
client.create()
.forPath("/test1", "curator data".getBytes(StandardCharsets.UTF_8));
System.out.println(client.getChildren().forPath("/"));
// 临时节点
client.create().withMode(CreateMode.EPHEMERAL)
.forPath("/secondPath", "hello world".getBytes(StandardCharsets.UTF_8));
System.out.println(new String(client.getData().forPath("/secondPath")));
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL)
.forPath("/abc", "hello".getBytes(StandardCharsets.UTF_8));
// 递归创建
client.create()
.creatingParentContainersIfNeeded()
.forPath("/secondPath1/sencond2/sencond3");
Thread.sleep(10000);
}
3. 核心机制二:Watcher 监听机制
Watcher 监听机制是 Zookeeper 解决各种分布式不一致疑难杂症的独家法门,也是学习 Zookeeper 必学的知识点。
3.1 对于 Watcher 机制的理解
Zookeeper 提供了数据的发布与订阅的功能,多个订阅者可以同时监听某一个对象,当这个对象自身状态发生变化时(例如节点数据或者节点的子节点个数变化),Zookeeper 系统会通知这些订阅者。
对于发布和订阅这个概念的理解,我们可以用这个场景来理解:
比如前两天的台风,老板想发一个通知给员工:明天在家办公。
于是老板会在钉钉群上 Ding 一个消息,员工自己打开钉钉查看。
在这个场景中,老板是发布者,员工是订阅者,钉钉群就是 Zookeeper 系统。
老板并不一一给员工发消息,而是把消息发到群里,员工就可以感知到消息的变化。
| 订阅者 | 员工 | 客户端1 |
|---|---|---|
| 系统 | 钉钉群 | Zookeeper系统 |
| 发布者 | 老板 | 客户端2 |
3.2 Watcher 机制的流程
客户端首先将 Watcher 注册到服务器上,同时将 Watcher 对象保存在客户端的 Watcher 管理器中。当 Zookeeper 服务端监听到数据状态发生变化时,服务端会首先主动通知客户端,接着客户端的 Watcher 管理器会触发相关的 Watcher 来回调响应的逻辑,从而完成整体的发布/订阅流程。
监听器 Watcher 的定义:
public interface Watcher {
// WatchedEvent 对象中有下面三个属性,Zookeeper状态,事件类型,路径
// final private KeeperState keeperState;
// final private EventType eventType;
// private String path;
abstract public void process(WatchedEvent event);
}
下面是监听的大致流程图:
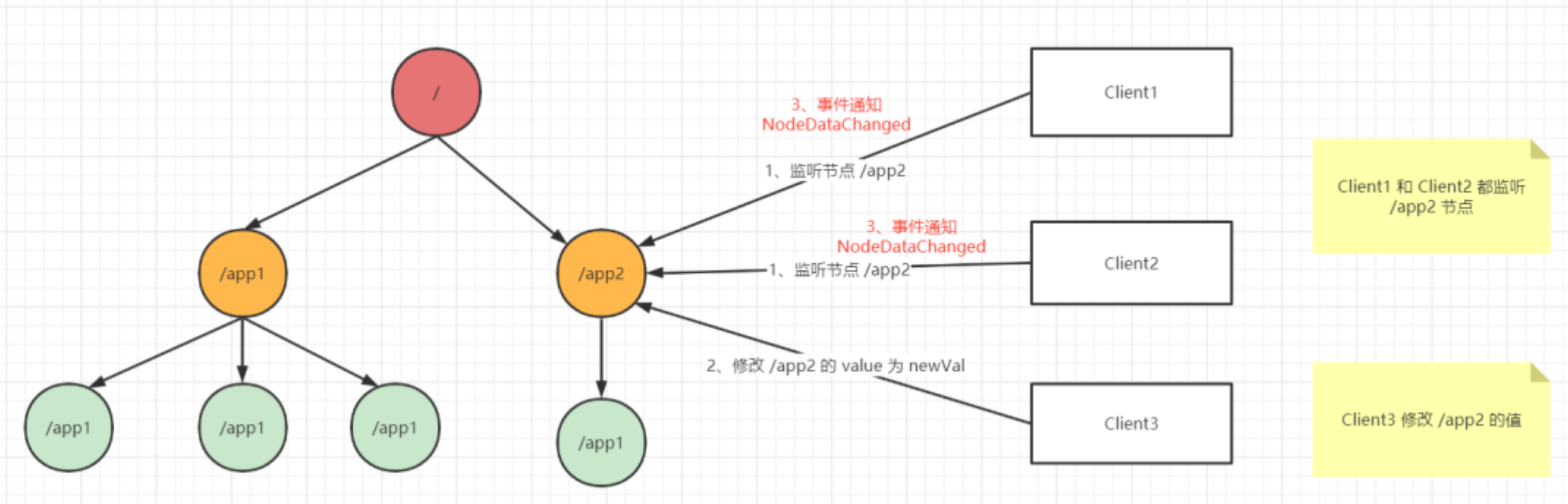
稍稍解释一下:
1、Client1 和 Client2 都关心 /app2 节点的数据状态变化,于是注册一个对于 /app2 的监听器到 Zookeeper 上;
2、当 Client3 修改 /app2 的值后,Zookeeper 会主动通知 Client1 和 Client2 ,并且回调监听器的方法
当然这里的数据状态变化有下面这些类型:
- 节点被创建;
- 节点被删除;
- 节点数据发生改变;
- 节点的子节点个数发生改变
3.3 通过代码来初步理解
我们还是用 Curator 框架来验证一下这个监听器
代码很简单,这里我们使用 TreeCache 表示对于 /app2 的监听,并且注册了监听的方法
public class CuratorWatcher {
public static void main(String[] args) throws Exception {
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("localhost:2181")
.connectionTimeoutMs(10000)
.retryPolicy(new ExponentialBackoffRetry(1000, 10))
.build();
client.start();
String path = "/app2";
TreeCache treeCache = new TreeCache(client, path);
treeCache.start();
treeCache.getListenable().addListener((client1, event) -> {
System.out.println("event.getData()," + event.getData());
System.out.println("event.getType()," + event.getType());
});
Thread.sleep(Integer.MAX_VALUE);
}
}
当 /app2 的状态发生变化时,就会调用监听的方法。
Curator 是对原生的 Zookeeper Api 有封装的,原生的 Zookeeper 提供的 Api ,注册监听后,当数据发生改变时,监听就被服务端删除了,要重复注册监听。
Curator 则对这个做了相应的封装和改进。
4. 代码实战:实现主备选举
这里我们主要想实现的功能是:
- 有两个节点,bigdata001,bigdata002 ,他们互相主备。
- bigdata001 启动时,往 zk 上注册一个临时节点 /ElectorLock(锁),并且往 /ActiveMaster 下面注册一个子节点,表示自己是主节点;
- bigdata002 启动时,发现临时节点 /ElectorLock 存在,表示当前系统已经有主节点了,则自己往 /StandbyMaster 下注册一个节点,表示自己是 standby。
- bigdata001 退出时,释放 /ElectorLock,并且删除 /activeMaster 下的节点。
- bigdata002 感知到 /ElectorLock 不存在时,则自己去注册 /ElectorLock,并在 /ActiveMaster 下注册自己,表示自己已经成为了主节点。
代码还是用 Curator 框架实现的:
package com.kkarch.zookeeper;
import cn.hutool.core.util.StrUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.recipes.cache.TreeCache;
import org.apache.curator.framework.recipes.cache.TreeCacheEvent;
import org.apache.zookeeper.CreateMode;
import java.nio.charset.StandardCharsets;
/**
* 分布式选举
*
* @Author wangkai
* @Time 2021/7/25 20:12
*/
@Slf4j
public class ElectorTest {
private static final String PARENT = "/cluster_ha";
private static final String ACTIVE = PARENT + "/ActiveMaster";
private static final String STANDBY = PARENT + "/StandbyMaster";
private static final String LOCK = PARENT + "/ElectorLock";
private static final String HOSTNAME = "bigdata05";
private static final String activeMasterPath = ACTIVE + "/" + HOSTNAME;
private static final String standByMasterPath = STANDBY + "/" + HOSTNAME;
public static void main(String[] args) throws Exception {
CuratorFramework zk = ZkUtil.createZkClient("localhost:2181");
zk.start();
// 注册好监听
TreeCache treeCache = new TreeCache(zk, PARENT);
treeCache.start();
treeCache.getListenable().addListener((client, event) -> {
if (event.getType().equals(TreeCacheEvent.Type.INITIALIZED) || event.getType().equals(TreeCacheEvent.Type.CONNECTION_LOST)
|| event.getType().equals(TreeCacheEvent.Type.CONNECTION_RECONNECTED) || event.getType().equals(TreeCacheEvent.Type.CONNECTION_SUSPENDED)) {
return;
}
System.out.println(event.getData());
// 如果 Active 下有节点被移除了,没有节点,则应该去竞选成为 Active
if (StrUtil.startWith(event.getData().getPath(), ACTIVE) && event.getType().equals(TreeCacheEvent.Type.NODE_REMOVED)) {
if (getChildrenNumber(zk, ACTIVE) == 0) {
createZNode(client, LOCK, HOSTNAME.getBytes(StandardCharsets.UTF_8), CreateMode.EPHEMERAL);
System.out.println(HOSTNAME + "争抢到了锁");
}
}
// 如果有锁节点被创建,则判断是不是自己创建的,如果是,则切换自己的状态为 ACTIVE
else if (StrUtil.equals(event.getData().getPath(), LOCK) && event.getType().equals(TreeCacheEvent.Type.NODE_ADDED)) {
if (StrUtil.equals(new String(event.getData().getData()), HOSTNAME)) {
createZNode(zk, activeMasterPath, HOSTNAME.getBytes(StandardCharsets.UTF_8), CreateMode.EPHEMERAL);
if (checkExists(client, standByMasterPath)) {
deleteZNode(client, standByMasterPath);
}
}
}
});
// 先创建 ACTIVE 和 STANDBY 节点
if (zk.checkExists().forPath(ACTIVE) == null) {
zk.create().creatingParentContainersIfNeeded().forPath(ACTIVE);
}
if (zk.checkExists().forPath(STANDBY) == null) {
zk.create().creatingParentContainersIfNeeded().forPath(STANDBY);
}
// 判断 ACTIVE 下是否有子节点,如果没有则去争抢一把锁
if (getChildrenNumber(zk, ACTIVE) == 0) {
createZNode(zk, LOCK, HOSTNAME.getBytes(StandardCharsets.UTF_8), CreateMode.EPHEMERAL);
}
// 如果有,则自己成为 STANDBY 状态
else {
createZNode(zk, standByMasterPath, HOSTNAME.getBytes(StandardCharsets.UTF_8), CreateMode.EPHEMERAL);
}
Thread.sleep(1000000000);
}
public static int getChildrenNumber(CuratorFramework client, String path) throws Exception {
return client.getChildren().forPath(path).size();
}
public static void createZNode(CuratorFramework client, String path, byte[] data, CreateMode mode) {
try {
client.create().withMode(mode).forPath(path, data);
} catch (Exception e) {
log.error("创建节点失败", e);
System.out.println("创建节点失败了");
}
}
public static boolean checkExists(CuratorFramework client, String path) throws Exception {
return client.checkExists().forPath(path) != null;
}
public static void deleteZNode(CuratorFramework client, String path) {
try {
if (checkExists(client, path)) {
client.delete().forPath(path);
}
} catch (Exception e) {
log.error("删除节点失败", e);
}
}
}


评论