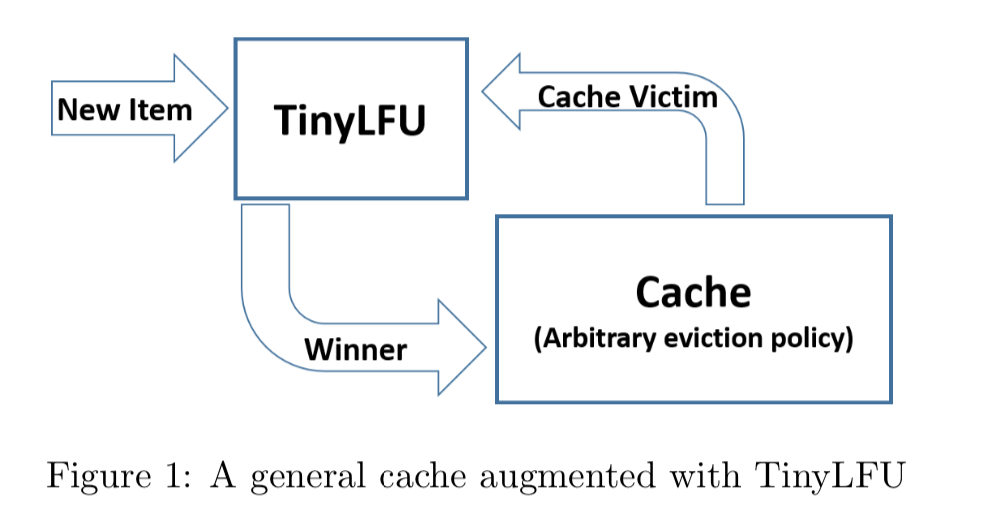
针对LFU存在记录访问频次的开销、对突发稀疏流量无能为力的现状;TinyLFU运用Count–Min Sketch 算法、保鲜机制尝试解决,它解决了一个问题,但它仍然无法较好的处理突发性的稀疏流量;TinyLFU之所以无法解决问题2,是因为新的记录(new items)还没来得及建立足够的频率就被剔除出去了,这就使得命中率下降,Window Tiny LFU使用3个LRU队列解决了这个问题,同时Caffeine使用了RingBuffer数据结构、WAL思想也是其高效的重要原因。
1. LRU 和 LFU 的缺点
- LRU 实现简单,在一般情况下能够表现出很好的命中率,是一个“性价比”很高的算法,平时也很常用。虽然 LRU 对
突发性的稀疏流量(sparse bursts)表现很好,但同时也会产生缓存污染,举例来说,如果偶然性的要对全量数据进行遍历,那么“历史访问记录”就会被刷走,造成污染。 - 如果数据的分布在一段时间内是固定的话,那么 LFU 可以达到最高的命中率。但是 LFU 有两个缺点,第一,它需要给每个记录项维护频率信息,每次访问都需要更新,这是个
巨大的开销;第二,对突发性的稀疏流量无力,因为前期经常访问的记录已经占用了缓存,偶然的流量不太可能会被保留下来,而且过去的一些大量被访问的记录在将来也不一定会使用上,这样就一直把“坑”占着了。
无论 LRU 还是 LFU 都有其各自的缺点,不过,现在已经有很多针对其缺点而改良、优化出来的变种算法。
2. TinyLFU
TinyLFU 就是其中一个优化算法,它是专门为了解决 LFU 上述提到的两个问题而被设计出来的。
解决第一个问题是采用了 Count–Min Sketch 算法。
解决第二个问题是让记录尽量保持相对的“新鲜”(Freshness Mechanism),并且当有新的记录插入时,可以让它跟老的记录进行“PK”,输者就会被淘汰,这样一些老的、不再需要的记录就会被剔除。
2.1 统计频率 Count–Min Sketch 算法
如何对一个 key 进行统计,但又可以节省空间呢?(不是简单的使用HashMap,这太消耗内存了),注意哦,不需要精确的统计,只需要一个近似值就可以了,怎么样,这样场景是不是很熟悉,如果你是老司机,或许已经联想到布隆过滤器(Bloom Filter)的应用了。
没错,将要介绍的 Count–Min Sketch 的原理跟 Bloom Filter 一样,只不过 Bloom Filter 只有 0 和 1 的值,那么你可以把 Count–Min Sketch 看作是“数值”版的 Bloom Filter。
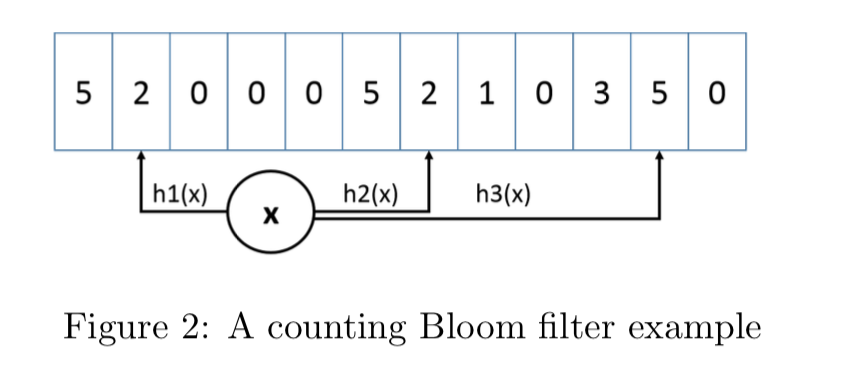
如果需要记录一个值,那我们需要通过多种Hash算法对其进行处理hash,然后在对应的hash算法的记录中+1,为什么需要多种hash算法呢?由于这是一个压缩算法必定会出现冲突,比如我们建立一个Long的数组,通过计算出每个数据的hash的位置。比如张三和李四,他们俩有可能hash值都是相同,比如都是1那Long[1]这个位置就会增加相应的频率,张三访问1万次,李四访问1次那Long[1]这个位置就是1万零1,如果取李四的访问评率的时候就会取出是1万零1,但是李四命名只访问了1次啊,为了解决这个问题,所以用了多个hash算法可以理解为long[][]二维数组的一个概念,比如在第一个算法张三和李四冲突了,但是在第二个,第三个中很大的概率不冲突,比如一个算法大概有1%的概率冲突,那四个算法一起冲突的概率是1%的四次方。通过这个模式我们取李四的访问率的时候取所有算法中,李四访问最低频率的次数。所以他的名字叫Count-Min Sketch。
2.2 保鲜机制
为了让缓存保持“新鲜”,剔除掉过往频率很高但之后不经常的缓存,Caffeine 有一个 Freshness Mechanism。做法很简答,就是当整体的统计计数(当前所有记录的频率统计之和,这个数值内部维护)达到某一个值时,那么所有记录的频率统计除以 2。
3. Window Tiny LFU
Caffeine 通过测试发现 TinyLFU 在面对突发性的稀疏流量(sparse bursts)时表现很差,因为新的记录(new items)还没来得及建立足够的频率就被剔除出去了,这就使得命中率下降。
于是 Caffeine 设计出一种新的 policy,即 Window Tiny LFU(W-TinyLFU),并通过实验和实践发现 W-TinyLFU 比 TinyLFU 表现的更好。
W-TinyLFU 的设计如下所示(两图等价):
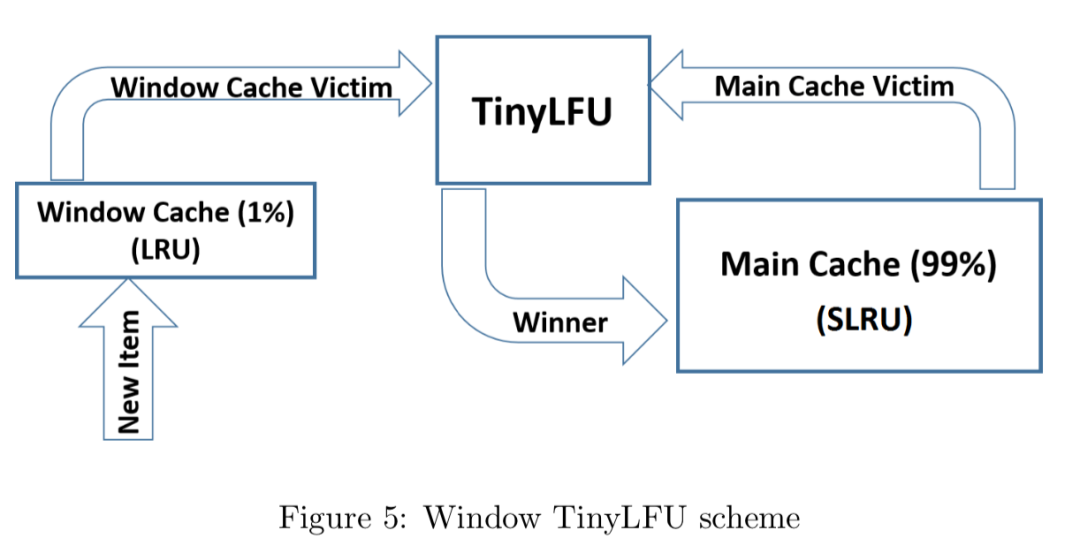
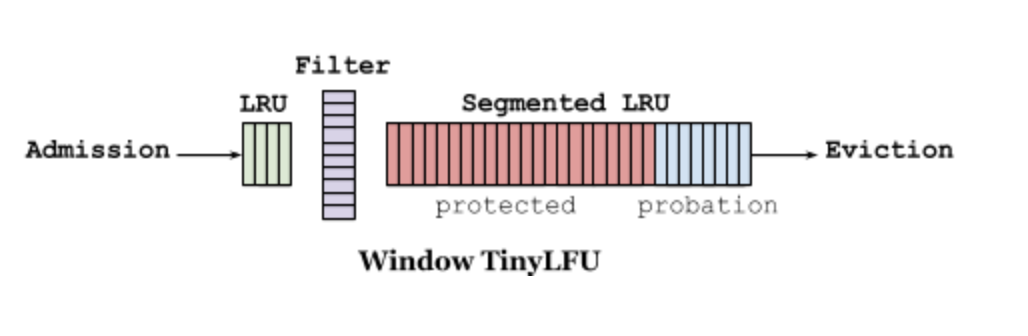
它主要包括两个缓存模块,主缓存是 SLRU(Segmented LRU,即分段 LRU),SLRU 包括一个名为 protected 和一个名为 probation 的缓存区。通过增加一个缓存区(即 Window Cache),当有新的记录插入时,会先在 window 区呆一下,就可以避免上述说的 sparse bursts 问题。
3.1 数据淘汰策略
在caffeine所有的数据都在ConcurrentHashMap中,这个和guava cache不同,guava cache是自己实现了个类似ConcurrentHashMap的结构。在caffeine中有三个记录引用的LRU队列:
- Eden队列:在caffeine中规定只能为缓存容量的1%,如果size=100,那这个队列的有效大小就等于1。这个队列中记录的是新到的数据,防止突发流量由于之前没有访问频率,而导致被淘汰。比如有一部新剧上线,在最开始其实是没有访问频率的,防止上线之后被其他缓存淘汰出去,而加入这个区域。伊甸区,最舒服最安逸的区域,在这里很难被其他数据淘汰。
- Probation队列:叫做缓刑队列,在这个队列就代表你的数据相对比较冷,马上就要被淘汰了。这个有效大小为size减去eden减去protected。
- Protected队列:在这个队列中,可以稍微放心一下了,你暂时不会被淘汰,但是别急,如果Probation队列没有数据了或者Protected数据满了,你也将会被面临淘汰的尴尬局面。当然想要变成这个队列,需要把Probation访问一次之后,就会提升为Protected队列。这个有效大小为(size减去eden) * 80% 如果size =100,就会是79。
这三个队列关系如下:
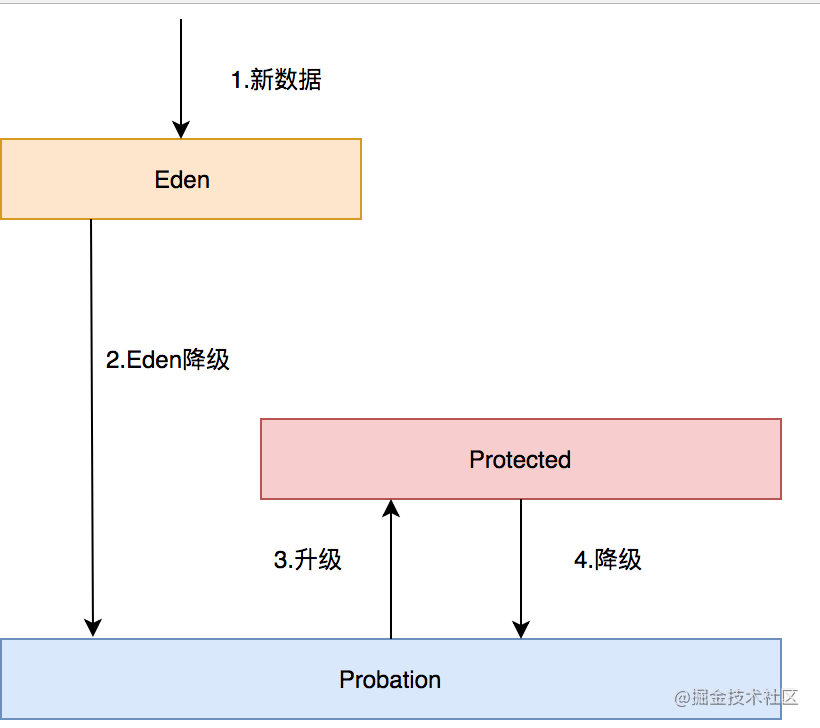
- 所有的新数据都会进入Eden。
- Eden满了,淘汰进入Probation。
- 如果在Probation中访问了其中某个数据,则这个数据升级为Protected。
- 如果Protected满了又会继续降级为Probation。
对于发生数据淘汰的时候,会从Probation中进行淘汰。会把这个队列中的数据队头称为受害者,这个队头肯定是最早进入的,按照LRU队列的算法的话那他其实他就应该被淘汰,但是在这里只能叫他受害者,这个队列是缓刑队列,代表马上要给他行刑了。这里会取出队尾叫候选者,也叫攻击者。这里受害者会和攻击者皇城PK决出我们应该被淘汰的。
通过我们的Count-Min Sketch中的记录的频率数据有以下几个判断:
-
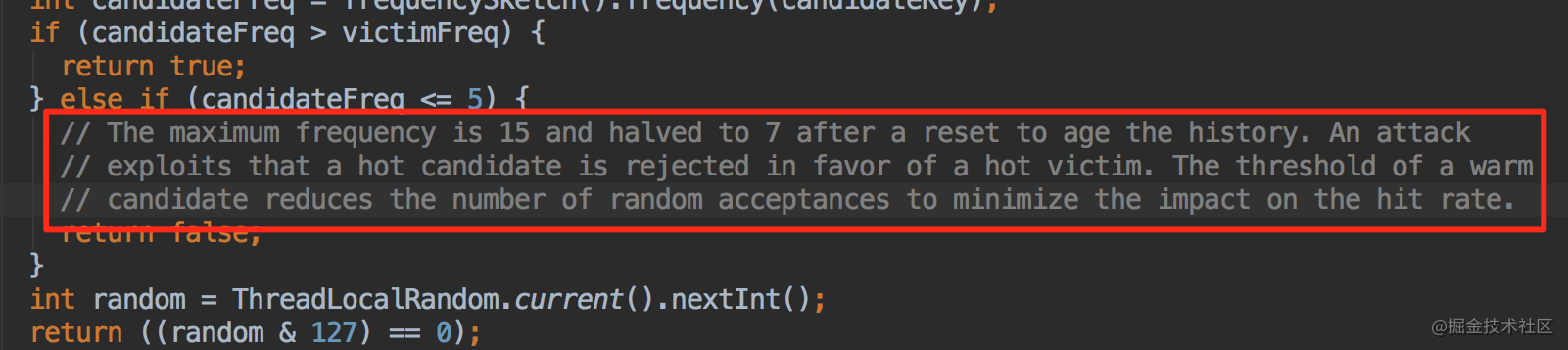
如果攻击者大于受害者,那么受害者就直接被淘汰。
-
如果攻击者<=5,那么直接淘汰攻击者。这个逻辑在他的注释中有解释:
他认为设置一个预热的门槛会让整体命中率更高。
-
其他情况,随机淘汰。
4. 异步高性能读写
对于异步高性能读写,有两个版本,一个版本强调RingBuffer的功劳,另外一个版本强调WAL(Write-Ahead Logging)的功劳。
RingBuffer版本:
在guava cache中我们说过其读写操作中夹杂着过期时间的处理,也就是你在一次Put操作中有可能还会做淘汰操作,虽然 Guava Cache 巧妙地利用了 JDK 的 ConcurrentHashMap(分段锁或者无锁 CAS)来降低锁的密度,达到提高并发度的目的,但是,对于一些热点数据,这种做法还是避免不了频繁的锁竞争,所以其读写性能会受到一定影响,可以看上面的图中,caffeine的确在读写操作上面完爆guava cache。主要是因为在caffeine,对这些事件的操作是通过异步操作,他将事件提交至队列,这里的队列的数据结构是RingBuffer,不清楚的可以看看这篇文章,你应该知道的高性能无锁队列Disruptor。然后会通过默认的ForkJoinPool.commonPool(),或者自己配置线程池,进行取队列操作,然后在进行后续的淘汰,过期操作。
WAL版本:
一般的缓存每次对数据处理完之后(读的话,已经存在则直接返回,不存在则 load 数据,保存,再返回;写的话,则直接插入或更新),但是因为要维护一些淘汰策略,则需要一些额外的操作,诸如:
- 计算和比较数据的是否过期
- 统计频率(像 LFU 或其变种)
- 维护 read queue 和 write queue
- 淘汰符合条件的数据
- 等等。。。
这种数据的读写伴随着缓存状态的变更,Guava Cache 的做法是把这些操作和读写操作放在一起,在一个同步加锁的操作中完成,虽然 Guava Cache 巧妙地利用了 JDK 的 ConcurrentHashMap(分段锁或者无锁 CAS)来降低锁的密度,达到提高并发度的目的。但是,对于一些热点数据,这种做法还是避免不了频繁的锁竞争。Caffeine 借鉴了数据库系统的 WAL(Write-Ahead Logging)思想,即先写日志再执行操作,这种思想同样适合缓存的,执行读写操作时,先把操作记录在缓冲区,然后在合适的时机异步、批量地执行缓冲区中的内容。但在执行缓冲区的内容时,也是需要在缓冲区加上同步锁的,不然存在并发问题,只不过这样就可以把对锁的竞争从缓存数据转移到对缓冲区上。
5. 总结
Caffeine 是一个优秀的本地缓存,通过使用 W-TinyLFU 算法, 基于Disruptor的异步高性能读写,使得它拥有高性能,高命中率(near optimal),低内存占用等特点。


评论