网关性能指标
流量网关:高性能,与具体的业务耦合少,专注转发,不用引入业务逻辑,不用维护lua脚本,不要专门的lua团队
业务网关:性能较高(没有指数级别的差距),与业务、技术栈相关,比如要通过Jar包和nacos、sential配合使用
Mock接口模拟20ms时延,报文大小约2K。
4核8G
| 分类 | 产品 | 600并发 QPS | 600并发 90% Latency(ms) | 1000并发 QPS | 1000并发 90% Latency(ms) |
|---|---|---|---|---|---|
| 后端服务 | 直接访问后端服务 | 23540 | 32.19 | 27325 | 52.09 |
| 流量网关 | kong v2.4.1 | 15662 | 50.87 | 17152 | 84.3 |
| 应用网关 | fizz-gateway-community v2.0.0 | 12206 | 65.76 | 12766 | 100.34 |
| 应用网关 | spring-cloud-gateway v2.2.9 | 11323 | 68.57 | 10472 | 127.59 |
| 应用网关 | shenyu v2.3.0 | 9284 | 92.98 | 9939 | 148.61 |
hashmap扩容机制
当map中包含的Entry的数量大于等于threshold = loadFactor * capacity的时候,且新建的Entry刚好落在一个非空的桶上,此刻触发扩容机制,将其容量扩大为2倍。调用resize扩容。
ConcurrentHashMap
JDK7
数据结构:ReentrantLock + Segment + HashEntry
map一个Segment数组,Segment又是一个HashEntry数组,HashEntry有next指针,是一个链表结构
元素查询:二次hash + 链表遍历,第一次Hash定位到Segment ,第二次Hash定位到元索所在的链表的头部
锁:Segment继承了ReentrantLock,锁定操作的Segment,其他的Segment不受影响,并发度为Segment个数,可以通过构造函数指定,数组扩容不会影晌其他Segment
JDK8
数据结构:synchronized + CAS + Node + 红黑树
其实 Node 和 HashEntry 的内容一样
元素查询:一次hash + 遍历红黑树(元素个数小于8的时候还是链表)
锁:锁链表的head节点,不影响其他元素的读写,锁粒度更细,效率更高,扩容时阻赛所有的读写操作、并发扩容
下面简单介绍下主要的几个方法的一些区别:
1. put() 方法
JDK1.7中的实现:
- 需要定位 2 次 (segments[i],segment中的table[i])
- 没获取到 segment锁的线程,没有权力进行put操作,不是像HashTable一样去挂起等待,而是会去做一下put操作前的准备:
- table[i]的位置(你的值要put到哪个桶中)
- 通过首节点first遍历链表找有没有相同key
- 在进行1、2的期间还不断自旋获取锁,超过
64次线程挂起!(单处理器自旋1次)
JDK1.8中的实现:
- 先根据 rehash值定位,拿到table[i]的 首节点first,然后:
- 如果为
null,通过CAS的方式把 value put进去 - 如果
非null,并且first.hash == -1,说明其他线程在扩容,参与一起扩容 - 如果
非null,并且first.hash != -1,Synchronized锁住 first节点,判断是链表还是红黑树,遍历插入。
- 如果为
2. get() 方法
JDK1.7中的实现:
- 由于变量
value是由volatile修饰的,java内存模型中的happen before规则保证了 对于 volatile 修饰的变量始终是写操作先于读操作的,并且还有 volatile 的内存可见性保证修改完的数据可以马上更新到主存中,所以能保证在并发情况下,读出来的数据是最新的数据。 - 如果get()到的是null值才去加锁。
JDK1.8中的实现:
- 和 JDK1.7类似
3. resize() 方法
JDK1.7中的实现:
- 跟HashMap的 resize() 没太大区别,都是在 put() 元素时去做的扩容,所以在1.7中的实现是获得了锁之后,在单线程中去做扩
new个2倍数组遍历old数组节点搬去新数组
JDK1.8中的实现:
- jdk1.8的扩容支持并发迁移节点,从old数组的尾部开始,如果该桶被其他线程处理过了,就创建一个 ForwardingNode 放到该桶的首节点,hash值为-1,其他线程判断hash值为-1后就知道该桶被处理过了。
4. 计算size
JDK1.7中的实现:
- 先采用不加锁的方式,计算两次,如果两次结果一样,说明是正确的,返回。
- 如果两次结果不一样,则把所有 segment 锁住,重新计算所有 segment的
Count的和
JDK1.8中的实现:
由于没有segment的概念,所以只需要用一个 baseCount 变量来记录ConcurrentHashMap 当前 节点的个数。
- 先尝试通过CAS 修改
baseCount - 如果多线程竞争激烈,某些线程CAS失败,那就CAS尝试将
CELLSBUSY置1,成功则可以把baseCount变化的次数暂存到一个数组counterCells里,后续数组counterCells的值会加到baseCount中。 - 如果
CELLSBUSY置1失败又会反复进行CASbaseCount和 CAScounterCells数组
印象深刻的经历
一次缓存优化经历
Redis使用频率很高,流量高峰期千兆网卡跑满,导致数据读取非常慢。
具体来说:假设应用接口的总访问次数是1000万,总缓存数据量大小50KB,一天要承受 500G 的数据流,平均每秒钟是 5.78M 的数据,高峰期按50倍估算,也就是说高峰期 Redis 服务每秒要传输超过 250 MB的数据,而千兆网卡的带宽只在120多MB。
此时,立马能想到的解决办法是:1. 升级到万兆网卡。2. 使用redis cluster模式,并增加redis节点数量,将流量分摊多多台机器上
但是,云服务器升级万兆网卡困难。增加节点使得成本攀升,并且此时数据量并不大,服务器负载并不高,仅仅是redis服务器数据吞吐量大。
另辟蹊径:先访问本地内存,再访问redis,降低redis的访问频率(节点间数据同步的方案 —— Redis Pub/Sub , JGroups , MQ)。
其他类似方案的缺陷:Ehcache集群模式 在应用节点之间传递完整缓存数据,这样岂不是会把应用服务器的带宽跑满?而,
J2Cache的问题:如果应用发生重启,本地缓存超时时间丢失。
未来方向:封装成一个进程,服务器安装后,其他开发语言的应用可以通过客户端连接使用。
go channel
https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-channel/
netty面试
spring单例vs多例
Spring Bean有五种作用域:
singleton , prototype, request , session , global session
默认是单例,可以通过xml配置bean多例,更方便的是用@Scope(“prototype”)注解。
Controller, Service, DAO默认都是单例的。
单例是线程不安全的,所以不要在类中使用状态可变的成员变量。
@Autowired 和 @Resourse区别
两者都可以写在字段和setter方法上
@Autowired是Spring中定义注解,@Resourse是JRE定义的注解
@Autowired默认按byType装配,需要按byName来装配,可以结合@Qualifier注解一起使用,@Resourse默认按byName装配,它有可以配置的属性 name和type
public class TestServiceImpl {
@Autowired
@Qualifier("userDao")
private UserDao userDao;
}
tcp三握四分 + SpringMVC 打开网站看
Spring设计模式
适配器 + 工厂 + 代理 + 单例
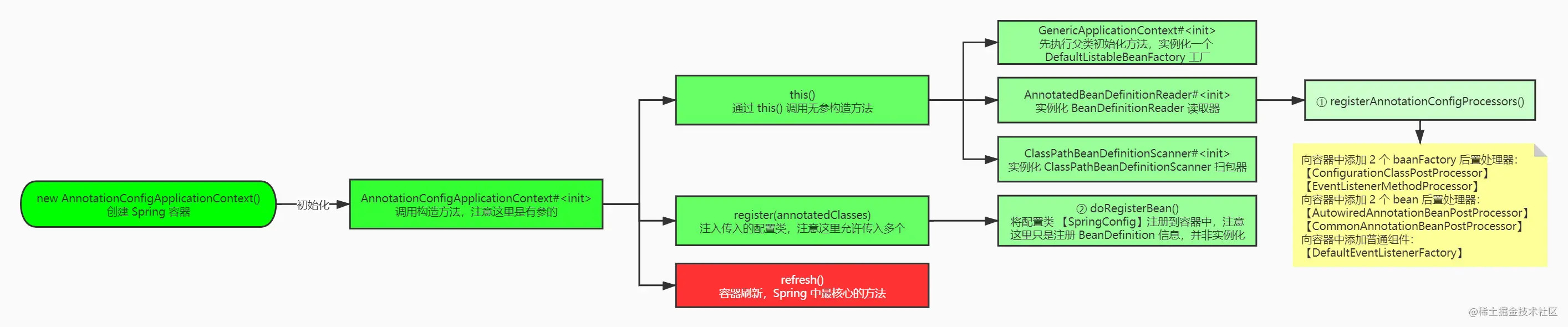
Spring启动流程
因为是基于 java-config 技术分析源码,所以这里的入口是 AnnotationConfigApplicationContext ,如果是使用 xml 分析,那么入口即为 ClassPathXmlApplicationContext ,它们俩的共同特征便是都继承了 AbstractApplicationContext 类,而大名鼎鼎的 refresh()便是在这个类中定义的。我们接着分析 AnnotationConfigApplicationContext 类,源码如下:
// 初始化容器
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
// 注册 Spring 内置后置处理器的 BeanDefinition 到容器
this();
// 注册配置类 BeanDefinition 到容器
register(annotatedClasses);
// 加载或者刷新容器中的Bean
refresh();
}
Spring的启动流程可以归纳为四个步骤:
-
创建Spring容器,如:new AnnotationConfigApplicationContext
-
初始化Spring容器
spring容器的初始化时,通过this()调用了无参构造函数,主要做了以下三个事情:
- 实例化BeanFactory【DefaultListableBeanFactory】工厂,用于生成Bean对象
- 实例化BeanDefinitionReader注解配置读取器,用于对特定注解(如@Service、@Repository)的类进行读取转化成 BeanDefinition 对象,(BeanDefinition 是 Spring 中极其重要的一个概念,它存储了 bean 对象的所有特征信息,如是否单例,是否懒加载,factoryBeanName 等)➕ 注册内置的BeanPostProcessor的BeanDefinition到容器中
- 实例化ClassPathBeanDefinitionScanner路径扫描器,用于对指定的包目录进行扫描查找 bean 对象
-
将配置类的BeanDefinition注册到容器中
-
调用refresh()方法刷新容器
数据库深分页优化
成因:大量回表 👉🏿 大量随机IO
即使前10000个会扔掉,mysql也会通过二级索引上的主键id,去聚簇索引上查一遍数据,这可是10000次随机io,自然慢成哈士奇。 这里可能会提出疑问,为什么会有这种行为,这是mysql优化器的坑,至今也没解决。
子查询优化: 如下只有10次回表
select xxx,xxx from in (select id from table where second_index = xxx limit 10 offset 10000)
**书签记录:**通过主键索引优化
SELECT * FROM cps_user_order_detail d WHERE d.id > #{maxId} AND d.order_time>'2020-8-5 00:00:00' ORDER BY d.order_time desc LIMIT 6;
id要是递增,不能跳页
ES + scroll + search_after
滚动翻页
RabbitMQ交换机类型
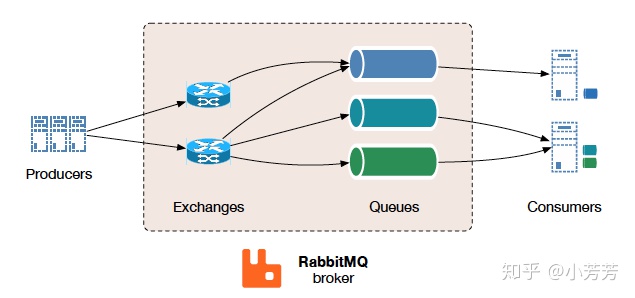
Exchange 的三种主要类型:Fanout、Direct 和 Topic
Fanout Exchange 会忽略 RoutingKey 的设置,直接将 Message 广播到所有绑定的 Queue 中,广播
Direct Exchange 是 RabbitMQ 默认的 Exchange,对 RoutingKey 是精确匹配,单播
Topic Exchange 支持对 RoutingKey 模糊匹配,多播
Java通过Executors提供四种线程池
分别为:
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可用线程,则新建线程。
- newFixedThreadPool创建一个****定长线程池****,可控制线程最大并发数,超出的线程会在队列中等待。
- ***newScheduledThreadPool*创建一个定长线程池,支持定时及周期性任务执行。
- *newSingleThreadExecutor* 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
常用Http状态码
301 Moved Permanently :永久重定向(优先使用301)
302 Found(临时重定向)
401 Unauthorized
403 Forbidden:资源不可用,防盗链
429 Too Many Requests
500 Internal Server Error
502 Bad Gateway
503 Service Unavailable
504 Gateway Timeout
Redis的Hashtable是如何扩容的
Redis渐进式rehash的好处在于它采取分而治之的方式,将rehash键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式rehash 而带来的庞大计算量。
ConcurrentHashMap多线程协同集中式扩容。在平均的情况下,是ConcurrentHashMap快。这也意味着,扩容时所需要花费的空间能够更快的进行释放。
对比:
- 扩容所花费的时间对比:ConcurrentHashMap平均更快
- 读操作,两者的性能相差不多
- 写操作,Redis的字典返回更快些
- 删除操作,与写一样
怎么选择?
- 如果内存资源吃紧,希望能够进行快速的扩容方便释放扩容时需要的辅助空间,且那么选择后者。
- 如果对于写和删除操作要求迅速,那么可以选择前者。


评论