2PC对多方资源进行全局锁定,非常影响性能,例如Spring JTA;3PC尝试解决2PC的问题,引入资源参与者超时机制,一方资源参与者不可用不至于导致全局资源锁定等措施,但是收效甚微,且使得交互流程变长变复杂;TCC需要业务系统自己针对每一个操作实现Try - Confirm - Cancel 方法,好处是可以跨数据库、跨不同的业务系统实现事务,坏处是与业务代码耦合(参考Seata的TCC模式);Saga参与者提交自己的本地事务,但是每个正向事务操作,就要对应一个逆向的补偿事务操作(参考Seata的Saga模式);性价比最高的分布式事务应该要数本地消息表;还可以使用RocketMQ消息事务,如果MQ不支持消息事务,可以使用MQ+本地消息表达到一样的效果。
分布式事务顾名思义就是要在分布式系统中实现事务,它其实是由多个本地事务组合而成。对于分布式事务而言几乎满足不了 ACID,其实对于单机事务而言大部分情况下也没有满足 ACID,不然怎么会有四种隔离级别呢?所以更别说分布在不同数据库或者不同应用上的分布式事务了。
2PC
2PC(Two-phase commit protocol),中文叫二阶段提交。 二阶段提交是一种强一致性设计,2PC 引入一个事务协调者的角色来协调管理各参与者(也可称之为各本地资源)的提交和回滚,二阶段分别指的是准备(投票)和提交两个阶段。
**准备阶段**协调者会给各参与者发送准备命令,你可以把准备命令理解成除了提交事务之外啥事都做完了。
同步等待所有资源的响应之后就进入第二阶段即**提交阶段**(注意提交阶段不一定是提交事务,也可能是回滚事务)。
假如在第一阶段所有参与者都返回准备成功,那么协调者则向所有参与者发送提交事务命令,然后等待所有事务都提交成功之后,返回事务执行成功。
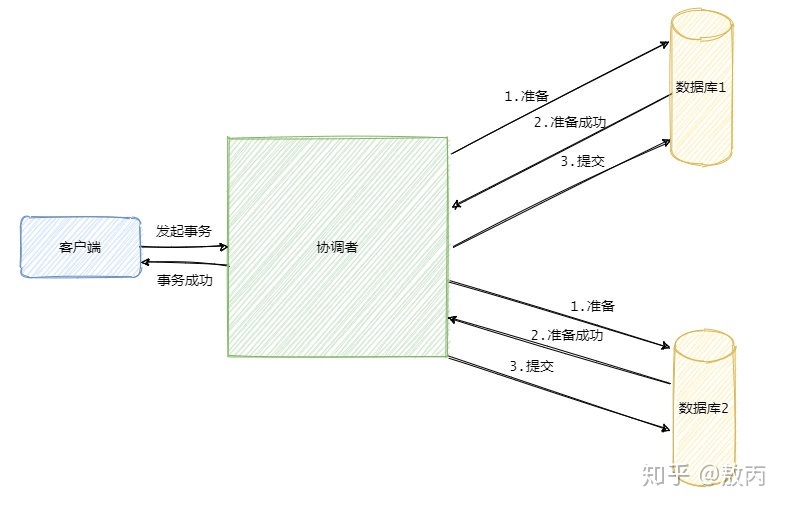
假如在第一阶段有一个参与者返回失败,那么协调者就会向所有参与者发送回滚事务的请求,即分布式事务执行失败。

首先 2PC 是一个同步阻塞协议,像第一阶段协调者会等待所有参与者响应才会进行下一步操作,当然第一阶段的协调者有超时机制,假设因为网络原因没有收到某参与者的响应或某参与者挂了,那么超时后就会判断事务失败,向所有参与者发送回滚命令。
在第二阶段协调者的没法超时,只能不断重试,这里有两种情况:
第一种是第二阶段执行的是回滚事务操作,那么答案是不断重试,直到所有参与者都回滚了,不然那些在第一阶段准备成功的参与者会一直阻塞着。
第二种是第二阶段执行的是提交事务操作,那么答案也是不断重试,因为有可能一些参与者的事务已经提交成功了,这个时候只有一条路,就是头铁往前冲,不断的重试,直到提交成功,到最后真的不行只能人工介入处理。
至此我们已经详细的分析的 2PC 的各种细节,我们来总结一下:
2PC 是一种尽量保证强一致性的分布式事务,因此它是同步阻塞的,而同步阻塞就导致长久的资源锁定问题,总体而言效率低,并且存在单点故障问题,在极端条件下存在数据不一致的风险。
当然具体的实现可以变形,而且 2PC 也有变种,例如 Tree 2PC、Dynamic 2PC。
还有一点不知道你们看出来没,2PC 适用于数据库层面的分布式事务场景,而我们业务需求有时候不仅仅关乎数据库,也有可能是上传一张图片或者发送一条短信。
而且像 Java 中的 JTA 只能解决一个应用下多数据库的分布式事务问题,跨服务了就不能用了。
简单说下 Java 中 JTA,它是基于XA规范实现的事务接口,这里的 XA 你可以简单理解为基于数据库的 XA 规范来实现的 2PC。
3PC
3PC 的出现是为了解决 2PC 的一些问题,相比于 2PC 它在参与者中也引入了超时机制,并且新增了一个阶段使得参与者可以利用这一个阶段统一各自的状态。
让我们来详细看一下。
3PC 包含了三个阶段,分别是**准备阶段、预提交阶段、提交阶段**,对应的英文就是:CanCommit、PreCommit 、 DoCommit。
看起来是把 2PC 的提交阶段变成了预提交阶段和提交阶段,但是 3PC 的准备阶段协调者只是询问参与者的自身状况,比如你现在还好吗?负载重不重?这类的。
而预提交阶段就是和 2PC 的准备阶段一样,除了事务的提交该做的都做了。
提交阶段和 2PC 的一样,让我们来看一下图。

不管哪一个阶段有参与者返回失败都会宣布事务失败,这和 2PC 是一样的(当然到最后的提交阶段和 2PC 一样只要是提交请求就只能不断重试)。
我们先来看一下 3PC 的阶段变更有什么影响。
首先准备阶段的变更成不会直接执行事务,而是会先去询问此时的参与者是否有条件接这个事务,因此不会一来就干活直接锁资源,使得在某些资源不可用的情况下所有参与者都阻塞着。
而预提交阶段的引入起到了一个统一状态的作用,它像一道栅栏,表明在预提交阶段前所有参与者其实还未都回应,在预处理阶段表明所有参与者都已经回应了。
假如你是一位参与者,你知道自己进入了预提交状态那你就可以推断出来其他参与者也都进入了预提交状态。
但是多引入一个阶段也多一个交互,因此性能会差一些,而且绝大部分的情况下资源应该都是可用的,这样等于每次明知可用执行还得询问一次。
我们再来看下参与者超时能带来什么样的影响。
我们知道 2PC 是同步阻塞的,上面我们已经分析了协调者挂在了提交请求还未发出去的时候是最伤的,所有参与者都已经锁定资源并且阻塞等待着。
那么引入了超时机制,参与者就不会傻等了,如果是等待提交命令超时,那么参与者就会提交事务了,因为都到了这一阶段了大概率是提交的,如果是等待预提交命令超时,那该干啥就干啥了,反正本来啥也没干。
然而超时机制也会带来数据不一致的问题,比如在等待提交命令时候超时了,参与者默认执行的是提交事务操作,但是有可能执行的是回滚操作,这样一来数据就不一致了。
当然 3PC 协调者超时还是在的,具体不分析了和 2PC 是一样的。
从维基百科上看,3PC 的引入是为了解决提交阶段 2PC 协调者和某参与者都挂了之后新选举的协调者不知道当前应该提交还是回滚的问题。
新协调者来的时候发现有一个参与者处于预提交或者提交阶段,那么表明已经经过了所有参与者的确认了,所以此时执行的就是提交命令。
所以说 3PC 就是通过引入预提交阶段来使得参与者之间的状态得到统一,也就是留了一个阶段让大家同步一下。
但是这也只能让协调者知道该如果做,但不能保证这样做一定对,这其实和上面 2PC 分析一致,因为挂了的参与者到底有没有执行事务无法断定。
所以说 3PC 通过预提交阶段可以减少故障恢复时候的复杂性,但是不能保证数据一致,除非挂了的那个参与者恢复。
让我们总结一下, 3PC 相对于 2PC 做了一定的改进:
引入了参与者超时机制
准备阶段不执行事务,不锁定资源,只是询问参与者状态,不至于使得在某些参与者资源不可用的情况下所有参与者都阻塞着。
增加了预提交阶段使得故障恢复之后协调者的决策复杂度降低
但整体的交互过程更长了,性能有所下降,并且还是会存在数据不一致问题。
所以 2PC 和 3PC 都不能保证数据100%一致,因此一般都需要有定时扫描补偿机制。
我再说下 3PC 我没有找到具体的实现,所以我认为 3PC 只是纯的理论上的东西,而且可以看到相比于 2PC 它是做了一些努力但是效果甚微,所以只做了解即可。
TCC
2PC 和 3PC 都是数据库层面的,而 TCC 是业务层面的分布式事务,就像我前面说的分布式事务不仅仅包括数据库的操作,还包括发送短信等,这时候 TCC 就派上用场了!
TCC 指的是Try - Confirm - Cancel。
- Try 指的是预留,即资源的预留和锁定,注意是预留。
- Confirm 指的是确认操作,这一步其实就是真正的执行了。
- Cancel 指的是撤销操作,可以理解为把预留阶段的动作撤销了。
其实从思想上看和 2PC 差不多,都是先试探性的执行,如果都可以那就真正的执行,如果不行就回滚。
比如说一个事务要执行A、B、C三个操作,那么先对三个操作执行预留动作。如果都预留成功了那么就执行确认操作,如果有一个预留失败那就都执行撤销动作。
我们来看下流程,TCC模型还有个事务管理者的角色,用来记录TCC全局事务状态并提交或者回滚事务。
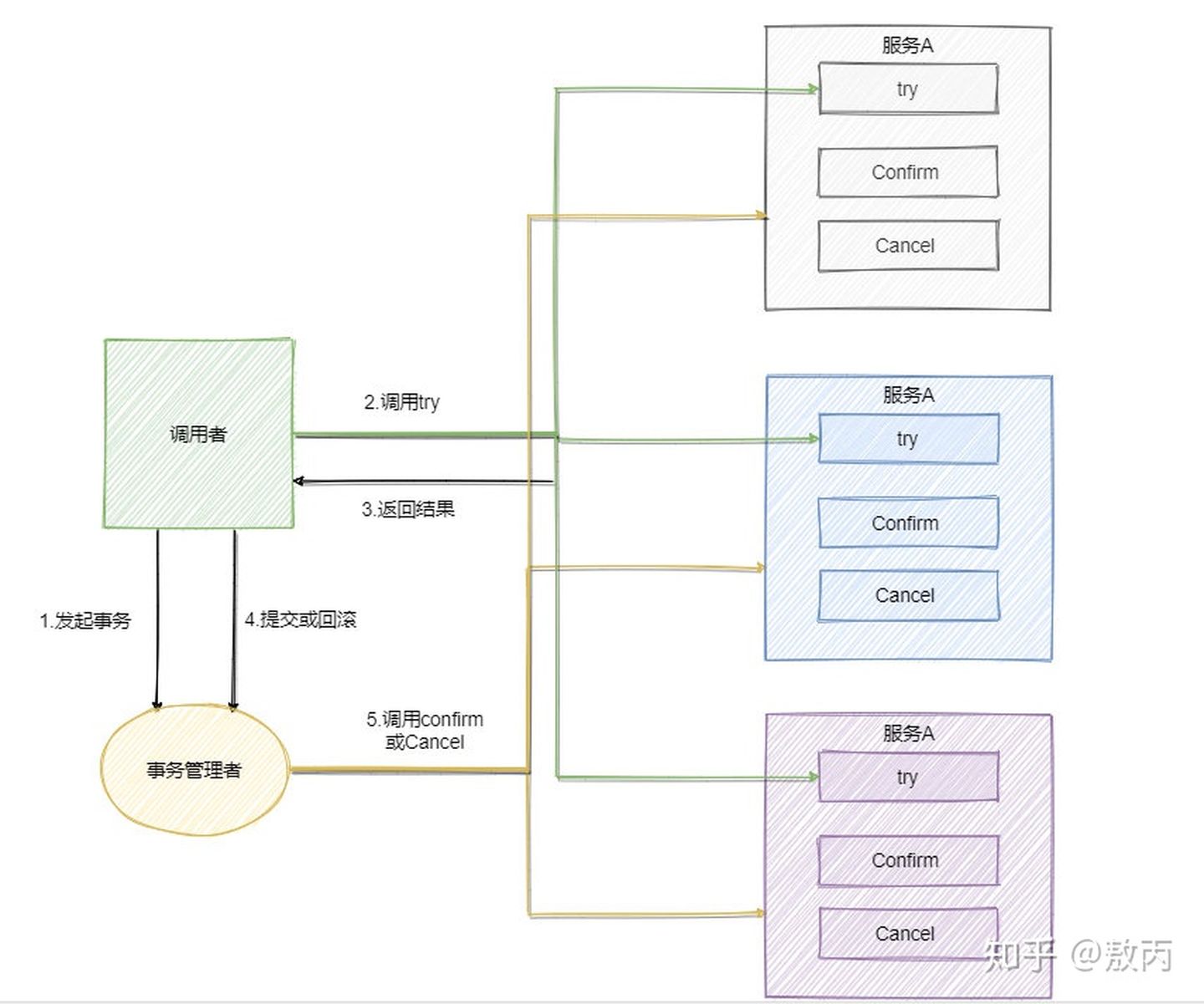
可以看到流程还是很简单的,难点在于业务上的定义,对于每一个操作你都需要定义三个动作分别对应Try - Confirm - Cancel。
因此 TCC 对业务的侵入较大和业务紧耦合,需要根据特定的场景和业务逻辑来设计相应的操作。
还有一点要注意,撤销和确认操作的执行可能需要重试,因此还需要保证操作的幂等。
相对于 2PC、3PC ,TCC 适用的范围更大,但是开发量也更大,毕竟都在业务上实现,而且有时候你会发现这三个方法还真不好写。不过也因为是在业务上实现的,所以TCC可以跨数据库、跨不同的业务系统来实现事务。
本地消息表
本地消息表其实就是利用了 各系统本地的事务来实现分布式事务。
本地消息表顾名思义就是会有一张存放本地消息的表,一般都是放在数据库中,然后在执行业务的时候 将业务的执行和将消息放入消息表中的操作放在同一个事务中,这样就能保证消息放入本地表中业务肯定是执行成功的。
然后再去调用下一个操作,如果下一个操作调用成功了好说,消息表的消息状态可以直接改成已成功。
如果调用失败也没事,会有 后台任务定时去读取本地消息表,筛选出还未成功的消息再调用对应的服务,服务更新成功了再变更消息的状态。
这时候有可能消息对应的操作不成功,因此也需要重试,重试就得保证对应服务的方法是幂等的,而且一般重试会有最大次数,超过最大次数可以记录下报警让人工处理。
可以看到本地消息表其实实现的是最终一致性,容忍了数据暂时不一致的情况。
本地消息表应用得相当广泛,除了上面的最终一致性方式,本地消息一般还可以这样实现:
例如保存订单数据的同时需要调用支付接口:
- 保存订单的时候将其状态设置为“待生效”
- 调用支付成功则更新订单状态 👉 “已生效”,调用失败则提示用户稍后再试
这个过程需要支付接口具备幂等性
消息事务
RocketMQ 就很好的支持了消息事务,让我们来看一下如何通过消息实现事务。
第一步先给 Broker 发送事务消息即半消息,半消息不是说一半消息,而是这个消息对消费者来说不可见,然后发送成功后发送方再执行本地事务。
再根据本地事务的结果向 Broker 发送 Commit 或者 RollBack 命令。
并且 RocketMQ 的发送方会提供一个反查事务状态接口,如果一段时间内半消息没有收到任何操作请求,那么 Broker 会通过反查接口得知发送方事务是否执行成功,然后执行 Commit 或者 RollBack 命令。
如果是 Commit 那么订阅方就能收到这条消息,然后再做对应的操作,做完了之后再消费这条消息即可。
如果是 RollBack 那么订阅方收不到这条消息,等于事务就没执行过。
可以看到通过 RocketMQ 还是比较容易实现的,RocketMQ 提供了事务消息的功能,我们只需要定义好事务反查接口即可。
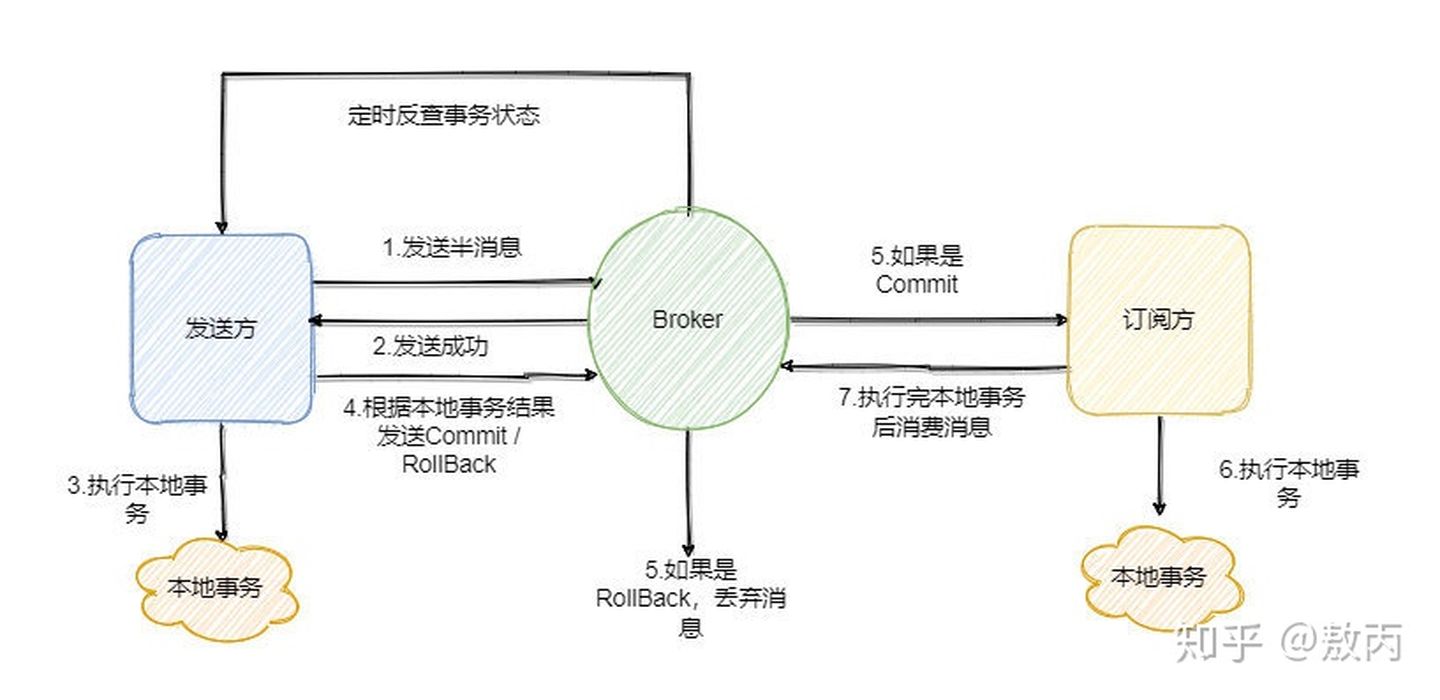
可以看到消息事务实现的也是最终一致性。
最大努力通知
其实我觉得本地消息表也可以算最大努力,事务消息也可以算最大努力。
就本地消息表来说会有后台任务定时去查看未完成的消息,然后去调用对应的服务,当一个消息多次调用都失败的时候可以记录下然后引入人工,或者直接舍弃。这其实算是最大努力了。
事务消息也是一样,当半消息被commit了之后确实就是普通消息了,如果订阅者一直不消费或者消费不了则会一直重试,到最后进入死信队列。其实这也算最大努力。
所以最大努力通知其实只是表明了一种柔性事务的思想:我已经尽力我最大的努力想达成事务的最终一致了。
适用于对时间不敏感的业务,例如短信通知。
Saga
在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
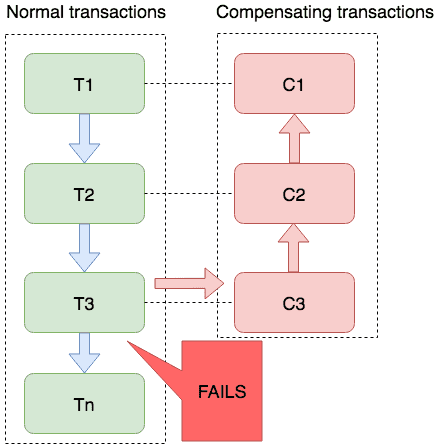
适用场景:
- 业务流程长、业务流程多
- 参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势:
- 一阶段提交本地事务,无锁,高性能
- 事件驱动架构,参与者可异步执行,高吞吐
- 补偿服务易于实现
缺点:
- 不保证隔离性
总结
可以看出 2PC 和 3PC 是一种强一致性事务,不过还是有数据不一致,阻塞等风险,而且只能用在数据库层面。
而 TCC 是一种补偿性事务思想,适用的范围更广,在业务层面实现,因此对业务的侵入性较大,每一个操作都需要实现对应的三个方法。
本地消息、事务消息和最大努力通知其实都是最终一致性事务,因此适用于一些对时间不敏感的业务。


评论