同步RPC存在线程利用率低、超时时间难以确定、雪崩效应等缺点。异步RPC能较好的解决这些问题。
1. 同步 RPC 调用面临的挑战
线程利用率低:线程资源是系统中非常重要的资源,在一个进程中线程总数是有限制的,提升线程使用率就能够有效提升系统的吞吐量,在同步 RPC 调用中,如果服务端没有返回响应,客户端业务线程就会一直阻塞,无法处理其它业务消息。纠结的超时时间:RPC 调用的超时时间配置是个比较棘手的问题。如果配置的过大,一旦服务端返回响应慢,就容易把客户端挂死。如果配置的过小,则超时失败率会增加。即便参考测试环境的平均和最大时延来设置,由于生产环境数据、硬件等与测试环境的差异,也很难一次设置的比较合理。另外,考虑到客户端流量的变化、服务端依赖的数据库、缓存、第三方系统等的性能波动,这都会导致服务调用时延发生变化,因此,依靠超时时间来保障系统的可靠性,难度很大。雪崩效应:在一个同步调用链中,只要下游某个服务返回响应慢,会导致故障沿着调用链向上游蔓延,最终把整个系统都拖垮,引起雪崩
2. 异步 RPC 调用的应用场景
2.1 缩短长流程的调用时延
对于一些逻辑上不存在互相依赖关系的服务,可以通过异步 RPC 调用,实现服务的并行调用,通过并行调用来降低服务调用总耗时。
2.2 服务调用耗时波动较大场景
对于一些业务场景,服务调用耗时与消息本身、调用的资源对象有关系,例如上传和下载接口,如果下载的资源较多则耗时就会相应的增加。对于这类场景,接口的调用超时时间比较难配置,如果配置过大,服务端自身响应慢之后会拖垮调用方,如果配置过小,万一遇到一个需要较长耗时的 RPC 调用就会超时。通过异步 RPC 调用,就不用再担心调用方业务线程被阻塞,超时时间可以相应配置大一些,减少超时导致的失败。
2.3 第三方接口调用
对于大部分的第三方服务调用,都需要采用防御性编程,防止因为第三方故障导致自身不能正常工作。如果采用同步 RPC 方式调用第三方服务,一旦第三方服务的处理耗时增加,就会导致客户端调用线程被阻塞,当超时时间配置不合理时,系统很容易被阻塞。通过异步化的 RPC 调用,可以防止被第三方服务端阻塞,Hystrix 的第三方故障隔离就是采用类似机制,只不过它底层创建了线程池,通过 Hystrix 的线程池将第三方服务调用与业务线程做了隔离,实现了非侵入式的故障隔离。
2.4 性能和资源利用率提升
对于一个同步串行化调用的系统,大量的业务线程都在等待服务端返回响应,系统的 CPU 使用率很低,但是性能却无法有效提升,这个问题几乎是所有采用同步 RPC 调用的业务都遇到的一个通病。要想充分利用 CPU 资源,需要让业务线程尽可能的跑满 CPU,而不是经常性的处于同步等待状态。采用异步 RPC 调用之后,在单位时间内业务线程可以接收并处理更多的请求消息,更充分的利用 CPU 资源,提升系统的吞吐量。
根据一些公开的测试数据,一些业务采用异步 RPC 替换同步 RPC 调用之后,综合性能提升 2-3 倍+。
3. 异步 RPC 实现原理
所谓异步回调,在得到结果之前,不会处于阻塞状态,理论上任何时间都没有任何线程处于阻塞状态,因此异步回调的模型,理论上只需要很少的工作线程与服务连接就能够达到很高的吞吐量。
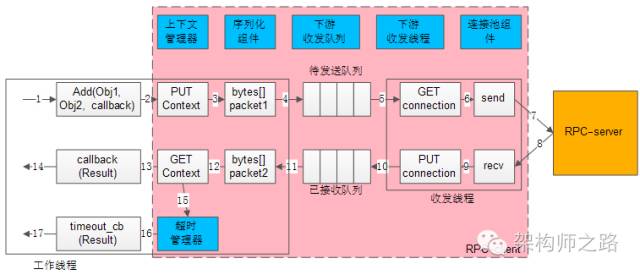
上图中左边的框框,是少量 工作线程(少数几个就行了)进行调用与回调。
中间粉色的框框,代表了RPC-client组件。
右边橙色框,代表了RPC-server。
蓝色六个小框,代表了异步RPC-client六个核心组件:上下文管理器,超时管理器,序列化组件,下游收发队列,下游收发线程,连接池组件。
白色的流程小框,以及箭头序号1-17,代表整个工作线程的串行执行步骤:
1)业务代码发起异步RPC调用,Add(Obj1,Obj2, callback)
2)上下文管理器,将请求,回调,上下文存储起来
3)序列化组件,将对象调用序列化成二进制字节流,可理解为一个待发送的包packet1
4)下游收发队列,将报文放入“待发送队列”,此时调用返回,不会阻塞工作线程
5)下游收发线程,将报文从“待发送队列”中取出,通过连接池组件拿到一个可用的连接connection
6)通过连接connection将包packet1发送给RPC-server
7)发送包在网络传输,发给RPC-server
8)响应包在网络传输,发回给RPC-client
9)通过连接connection从RPC-server收取响应包packet2
10)下游收发线程,将报文放入“已接受队列”,通过连接池组件,将conneciont放回连接池
11)下游收发队列里,报文被取出,此时回调将要开始,不会阻塞工作线程
12)序列化组件,将packet2范序列化为Result对象
13)上下文管理器,将结果,回调,上下文取出
14)通过callback回调业务代码,返回Result结果,工作线程继续往下走
如果请求长时间不返回,处理流程是:
15)上下文管理器,请求长时间没有返回
16)超时管理器拿到超时的上下文
17)通过timeout_cb回调业务代码,工作线程继续往下走
3.1 为什么需要上下文管理器?
回答:由于请求包的发送,响应包的回调都是异步的,甚至不在同一个工作线程中完成,需要一个组件来记录一个请求的上下文,把 请求-响应-回调 等一些信息匹配起来。
3.2 如何将 请求-响应-回调 这些信息匹配起来?
这是一个很有意思的问题,通过一条连接往下游服务发送了a,b,c三个请求包,异步的收到了x,y,z三个响应包:
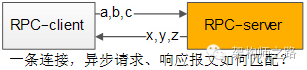
(1)怎么知道哪个请求包与哪个响应包对应?
(2)怎么知道哪个响应包与哪个回调函数对应?
回答:这是通过【请求id】来实现 请求-响应-回调 的串联的。
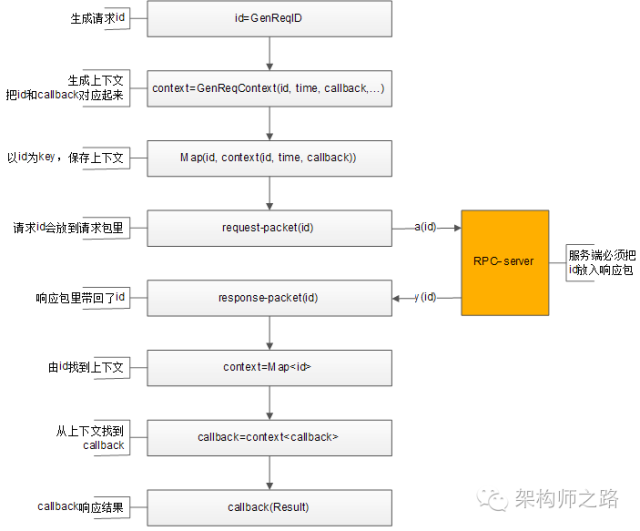
整个处理流程如上,通过请求id,上下文管理器来对应请求-响应-callback之间的映射关系:
1)生成请求id
2)生成请求上下文context,上下文中包含发送时间time,回调函数callback等信息
3)上下文管理器记录req-id与上下文context的映射关系,
4)将req-id打在请求包里发给RPC-server
5)RPC-server将req-id打在响应包里返回
6)由响应包中的req-id,通过上下文管理器找到原来的上下文context
7)从上下文context中拿到回调函数callback
8)callback将Result带回,推动业务的进一步执行
3.3 如何实现负载均衡,故障转移?
回答:与同步的连接池思路相同。不同在于,同步连接池使用阻塞方式收发,需要与一个服务的一个ip建立多条连接,异步收发,一个服务的一个ip只需要建立少量的连接(例如,一条tcp连接)。
3.4 如何实现超时发送与接收?
回答:同步阻塞发送,可以直接使用带超时的send/recv来实现,异步非阻塞的nio的网络报文收发,如何实现超时接收呢?(由于连接不会一直等待回包,那如何知晓超时呢?)这时,超时管理器就上场啦。
超时管理器 和 上下文管理器:
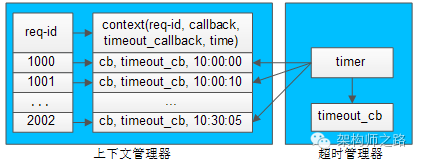
超时管理器,用于实现请求回包超时回调处理。
每一个请求发送给下游RPC-server,会在上下文管理器中保存req-id与上下文的信息,上下文中保存了请求很多相关信息,例如req-id,回包回调,超时回调,发送时间等。
超时管理器启动timer对上下文管理器中的context进行扫描,看上下文中请求发送时间是否过长,如果过长,就不再等待回包,直接超时回调,推动业务流程继续往下走,并将上下文删除掉。
如果超时回调执行后,正常的回包又到达,通过req-id在上下文管理器里找不到上下文,就直接将请求丢弃(因为已经超时处理过了)。
however,异步回调和同步回调相比,除了序列化组件和连接池组件,会多出上下文管理器,超时管理器,下游收发队列,下游收发线程等组件,并且对调用方的调用习惯有影响(同步->回调)。异步回调能提高系统整体的吞吐量,具体使用哪种方式实现RPC-client,可以结合业务场景来选取(对时延敏感的可以选用同步,对吞吐量敏感的可以选用异步)。
4. dubbo异步调用
dubbo实现异步调用的原理:
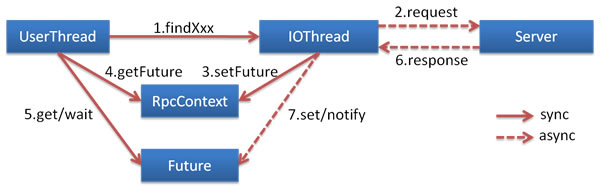
其原理和本文原理类似。
dubbo官方提供3种调用方式 👉 异步调用
其中 使用 RpcContext 的方式又可以细分成: 1.需要修改 Dubbo xml 配置文件或者注解 2. 无需修改任何配置文件,我们可以直接通过RpcContext#asyncCall异步完成方法调用 👉 Dubbo 同步调用太慢,也许你可以试试异步处理


评论